
| ホームページ | Pirikaで化学 | ブログ | 業務リスト | お問い合わせ |
| Pirikaで化学トップ | 情報化学+教育 | HSP | 化学全般 |
| 情報化学+教育トップ | 情報化学 | MAGICIAN | MOOC | プログラミング |
2003.10.22
自分はニューラルネットワークなどの手法を駆使して物性推算式を構築しています。
こうした物性推算式がなぜ必要なのでしょうか?
例えば塩素を含んだフロンはオゾン層を破壊するので使えなくなりました。
それにかわる化合物を作った場合に「その化合物の表面張力はいくつになるか実際に化合物を作る前に知りたい」という要求に応えることができます。
化合物の表面張力がいくつに成るかの推算式を構築する場合にはそのデータを収集します。
(pirikaでの推算式はそうした膨大なデータベースにもとづいています。)
どんどんデータを収集してくるとデータベースの問題点で指摘したように同じ化合物なのに実験結果が大きく違うものが出てきます。
例えば、CH2(OH)CH(OH)CH3という化合物。35.5dyn/cmというデータベースと72dyn/cmというデータベースがあります。
35.5dyn/cmというデータを信じて中間層を3として291化合物のデータからニューラルネットワークを構築してみます。すると下の図のようになります。
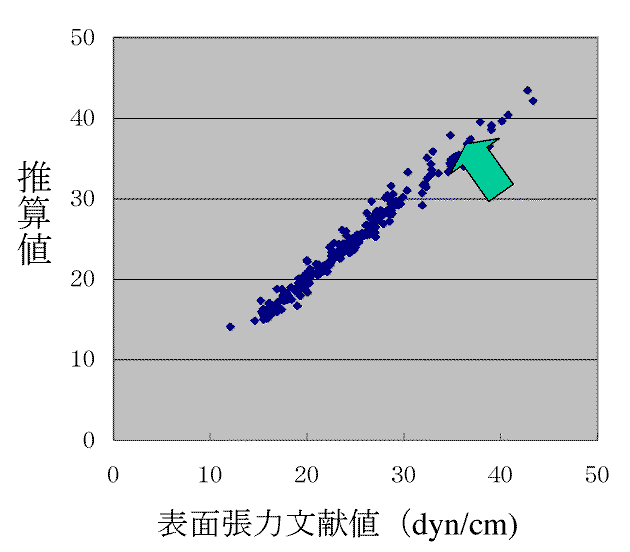
そこそこの精度で表面張力を推算できるニューラルネットワークが構築されます。
ですからこのCH2(OH)CH(OH)CH3という化合物の表面張力は35.5dyn/cmで72dyn/cmというデータは間違いかなと思ってしまいます。
しかし念のため72dyn/cmという値で同じようにニューラルネットワークを構築してみると、下図のようにやはりきれいに直線の上に乗ってきます。
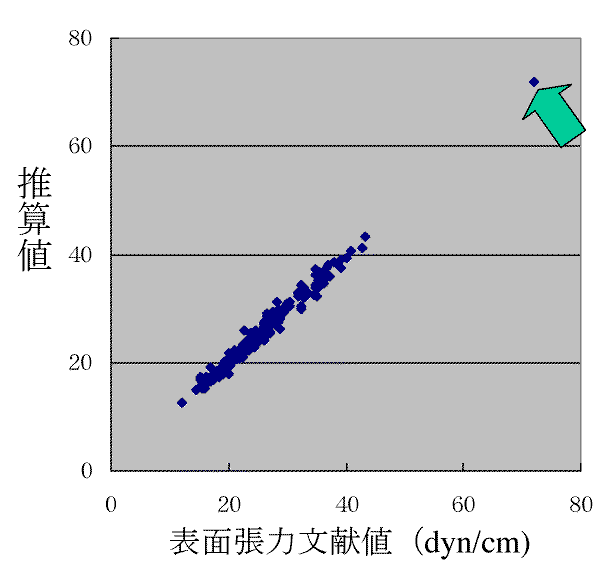
この例では72dyn/cmという値は母集団から明らかに突出しているので怪しいデータだとは見当がつきますが、多くの場合直線の上に乗ってしまうと怪しいデータの抽出はできません。
いつもこうなるとは限りませんがこの表面張力の場合には、中間層の数を3から2に減らしてみると、72dyn/cmという文献値に対する推算値は40dyn/cm付近になりやはり35.5dyn/cmの方が正しそうだと分かってきます。
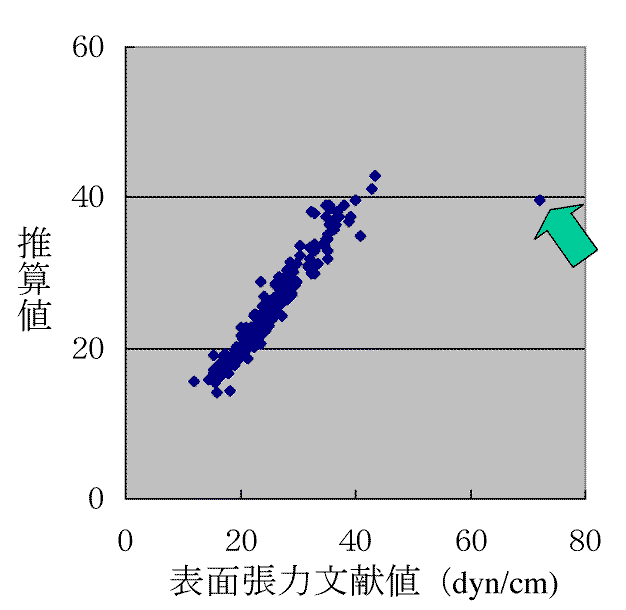
このように誤ったデータが遊離してくるのは非常に稀で通常はこうしたデータの矛盾、打ち込みミス、単位の取り違えなどからなかなか推算精度があがってきません。
推算に使うデータセットとしてどの値を使うか(使わないか)を選択するのが推算式を構築する際の最も重要な操作になります。
ニューラルネットワークは非常に強力なFitting能力を持つ為、入力値に誤りがあっても推算式を構築してしまう。
こうした性質からデータベースがあやふやだと非常に困ったことになってしまうのです。
では重回帰のような線形式を使えばこのような非線形解にまつわる面倒はないのではと思うかもしれませんが、なかなか線形式では推算の精度が出なかったり、線形から外れるものが研究のターゲットだったり(それを取り除いてしまっては意味がない)で、このデータが正しいと言い切るのは非常に難しい問題です。
情報の研究者と実験系の研究者の連携が重要になってくると思います。
物性研究をなさっている研究者の方で興味を持たれた方がいらっしゃいましたらご連絡下さい。
Copyright pirika.com since 1999-
Mail: yamahiroXpirika.com (Xを@に置き換えてください) メールの件名は[pirika]で始めてください。