
2021.10.29
情報化学+教育 > MAGICIAN 養成講座 > 配合処方設計トップ > 塗料の配合処方設計
MAGICIAN(MAterials Genome/Informatics and Chemo-Informatics Associate Networks)
MAGICIANとは、材料ゲノム(Materials Genome)、材料情報学(Materials Informatics)、情報化学(Chemo-Informatics)を結びつけて(Associate)ネットワーク(Networks)を構築していかれる人財です。
MIRAIの基本的な仕様は既に説明した。
ここでは塗料用の配合処方設計にMIRAIを使った例を紹介する。
解析したいデータの例
フッ素ポリマーと炭化水素系のポリマーの混合物の粉体塗料を考える。フッ素ポリマーは耐候性に優れる塗膜を与えるが高価である。
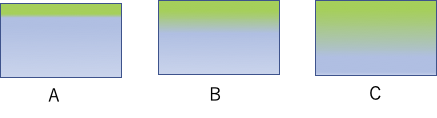
Aのような塗装になると、フッ素ポリマー(緑)と炭化水素系のポリマー(青)の境界で剥離してしまう恐れがある。
Cの様な塗装になると、高価なフッ素ポリマーを大量に使う割に、表面に一部ある炭化水素系のポリマーが性能の劣化を引き起こす。
Bの塗装のように、塗装表面にはフッ素ポリマーが偏在して耐候性を担い、ポリマーの境界では徐々に組成が変化し層間剥離を起こしにくい構造が好ましい。
大日本塗料の特許(JP WO2013/186832)はこの様な粉体塗装を実現する。
この特許では次のような成分を配合する。
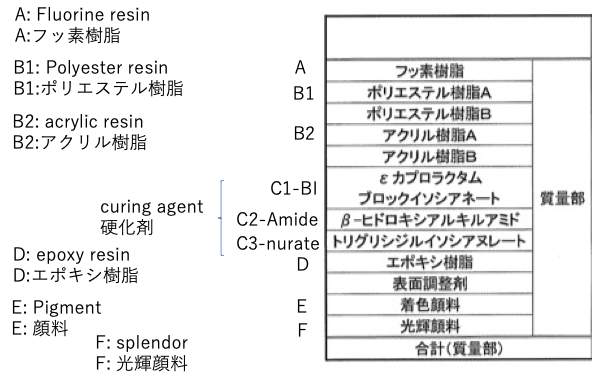
ポリエステル樹脂Bとアクリル樹脂Bはテーブルにはあるが、使われた実験は無い。
作成された塗膜は次の様な評価が行われている。その中の5つについて解析を行う。
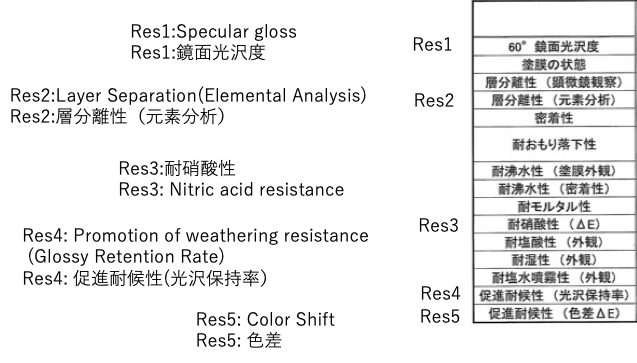
次のデータを全てコピーして表計算ソフトにペーストしておこう。
データの意味は次の様になる。
特許のデータを打ち込む。
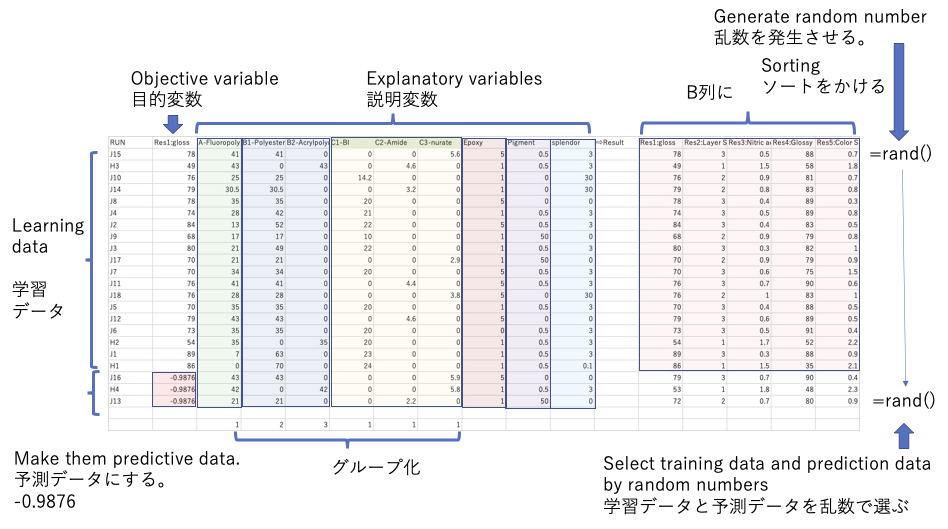
それができたら、まず学習用のデータと予測用のデータに分ける。それには、テーブルの最後の列に乱数を発生させて、ソートをかける。そして行の最後のいくつかを予測データにする。予測用のデータの目的変数には-0.9876を入れる。
その際に、学習用のデータセットには値が無いが、予測データセットに値がある場合には入れ替えが必要になる。(学習しなかったことに対しては答えを出せない。)
予測用のデータセットは、学習に含めなくても良いが、含める時には値を-0.9876にする。
MIRAIでは指数関数の掛け算で物性推算式を作成する。
(線形関数)^指数
学習データで作成した線形関数を予測データに適用した際に括弧の中がマイナスになってしまうことが稀にある。
この破綻を避けるため、説明変数のアウトラインを全て入れておく方が好ましい。
最後に、説明変数の似たものを同じグループに分ける。ここでは炭化水素ポリマーをB1,B2にするのと、硬化剤3種類をC1,C2,C3と同じグループにする。
データはタブ区切りでWebアプリにペーストするので、エクセルなどに整理しておくと便利である。

そしてメインテーブルとグループ分けをMIRAIにコピー&ペーストし、MIRAI Read ボタンをクリックする。
そして、計算結果を取り出す時には、STOPボタンを押す。そしてMIRAIが吐き出した式をコピーしエクセルの2行目に貼り付ける。この式を正しく作成するために各行と列は確実に制御される必要がある。
1行目、1列目はタイトル、2列目は目的変数は変えてはいけない。
STOPの後、STARTボタンを押すと続きが計算される。値が収束するまで計算を継続する。
ターゲットの物性値が数値の場合にはそのまま数値を使い、◯X△などは適宜数値に直して学習させる。
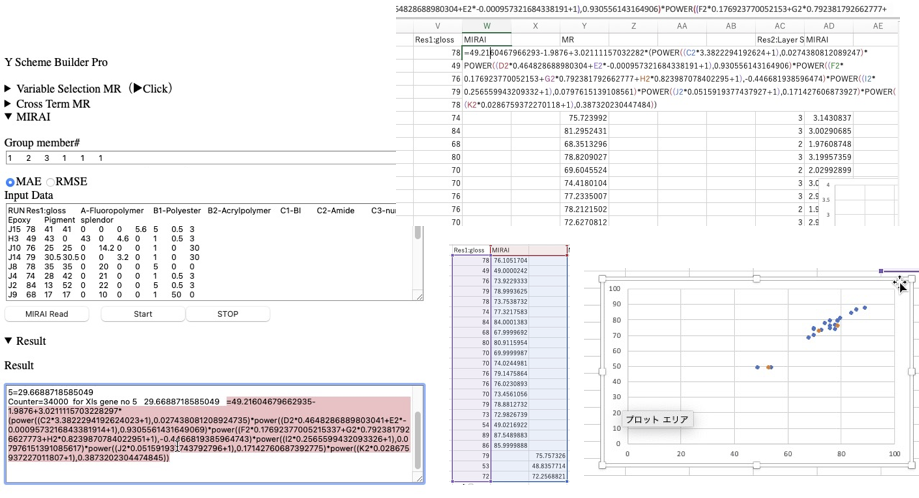
STOPボタンを押して計算を中断する。=の後の計算式をコピーする。エクセルの適当な2行目にペーストする。計算値を全体に広げ、予測値の部分は列を変える。そしてグラフ化する。値が変化しなくなるまで計算を継続する。
MIRAIとの比較するために、通常の重回帰計算を行う。
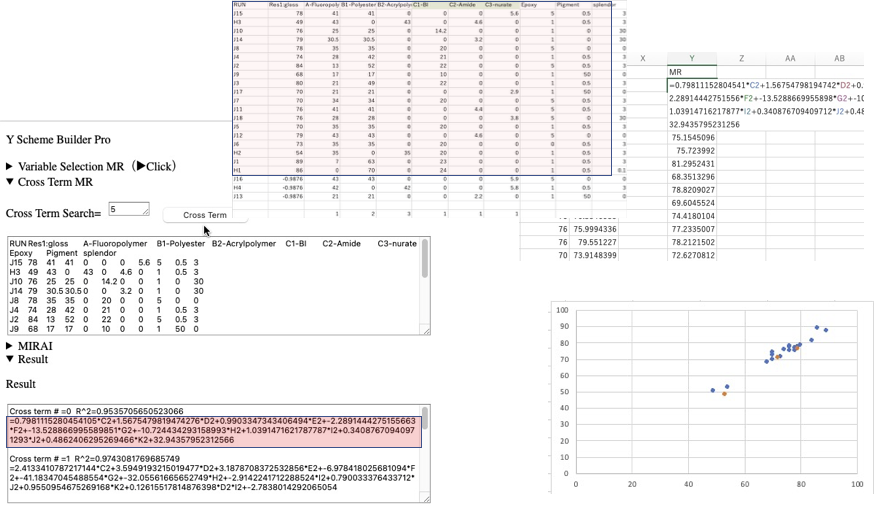
通常の重回帰計算するときは、予測データは含めない。YSBのCross Term MRを開きそこにデータセットをペーストする。Cross Termボタンを押すとResultに結果が表示される。CT=0が通常の重回帰の結果なので、それをエクセルに戻しグラフを作成する。
同じように、他の4つの物性についても計算する。
Res1:鏡面光沢度だけは重回帰法(MR)でも十分な記述性と予測性を持つ。
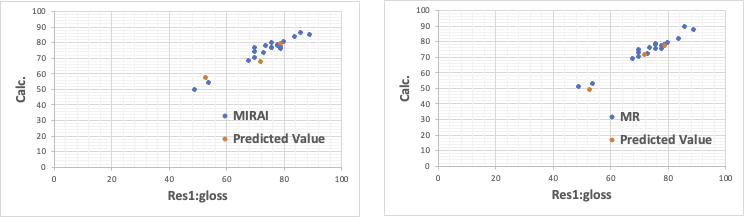
それ以外の結果は、明らかにMIRAIの方が重回帰法(MR)より優れている。
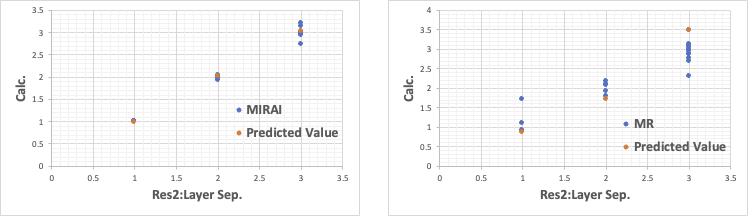
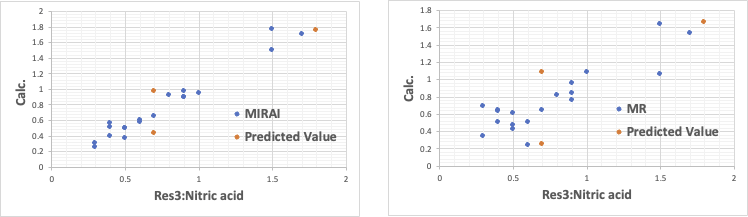
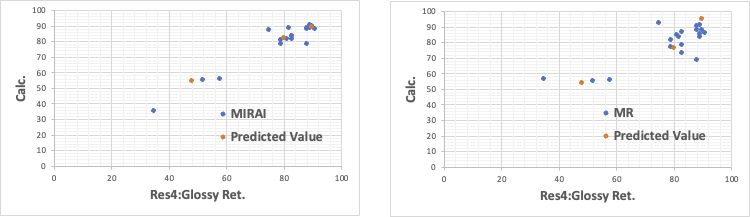
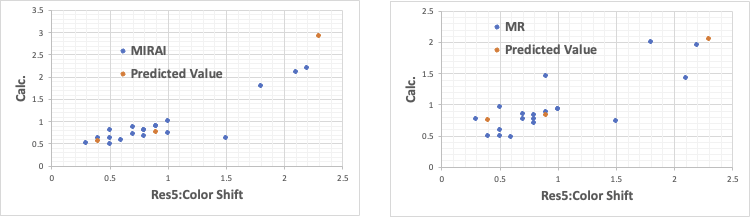
この様な精度の高い推算式が構築できると、後はシミュレーションだけで最適処方を自動設計することができる。
MIRAI (Multiple Index Regression for AI)がAI用の推算式として優れている所以である。
塗料解析例2
水性顔料分散体及びその製造方法
DIC株式会社の、JP 2019-189852は、樹脂、顔料、溶媒の配合をハンセンの溶解球と相互作用半径から規定した特許です。
樹脂や顔料を様々なHSPが既知の溶媒で溶解試験、分散試験を行うと、対象のHSPの中心値と相互作用半径を求めることができる。その中心から相互作用半径の球を描くと、ハンセンの溶解球を得ることができる。
ある溶媒、顔料などのHSPが、この相互作用半径の中に入ってくると、その対象に溶解する可能性が高くなる。
Web app Sphere Viewer
Drag=回転, Drag+Shift キー=拡大、縮小, Drag+コマンドキーかAltキー=移動。
溶媒をクリックすれば溶媒の名前が現れる。
いくつかのポリマーは、疎水的領域と親水的領域を持つことがある。
このDICの特許では、次の様な関係になるようにクレームしている。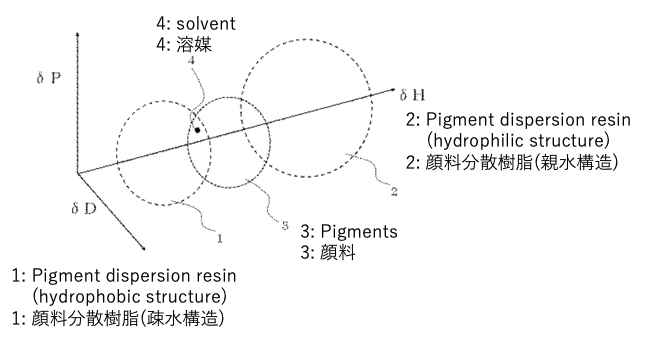
顔料の溶解球は樹脂疎水領域の溶解球と重なる(Scheme1)。
溶媒のHSPは顔料の溶解球の内側にある(Scheme2)。
溶媒のHSPは樹脂疎水領域の溶解球の内側にある(Scheme3)。
溶媒のHSPは樹脂親水領域の溶解球の外側にある(Scheme4)。
顔料は8種類、樹脂は5種類、4種類のHSP距離(Scheme1-4)については所定の方法で計算を行った。
目的変数は体積平均の粒子径(nm)で、これが大きいと粗大粒子が多く分散性が低い塗料となる。
MIRAIを使ってこの系を解析する時には、2種類の誤差の取り方で計算を行うことができる。
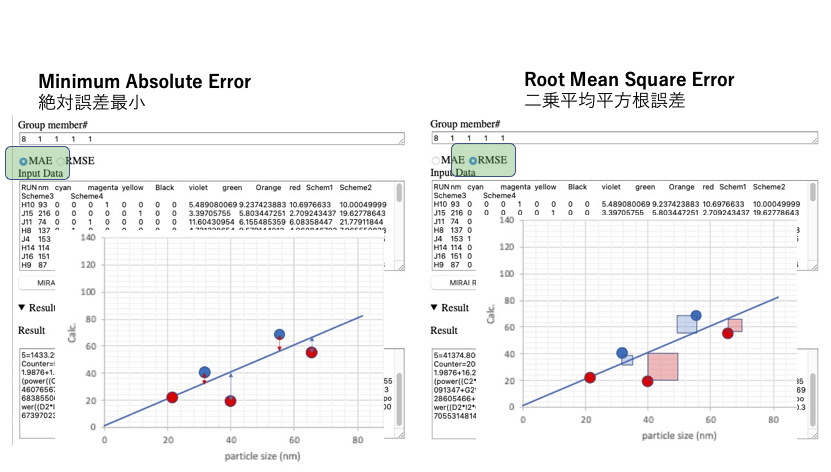
絶対誤差最小(MAE)を使うと、教師値と計算値の差の絶対値の総和を一番小さくしようと係数を定める。
すると、大きく外れるものはさらに外れ、他のものはどんどん直線に乗って来る。
入力間違いなど、怪しいデータを特定するときはとても有用である。
二乗平均平方根誤差(RMSE)を使うと大きな誤差を持つものを直線に近づけようとする。小さな誤差を各点に割り振る。小さな誤差は2乗すると、とても小さくなり影響を与えなくなる。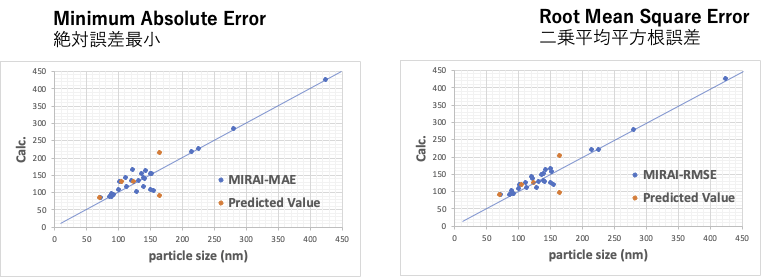
通常の重回帰解析も、自乗誤差を小さくするが、非線形性や項目間の相互作用を加味でき無いため、大きく外れるものが出てきて、相関係数をとても悪くする。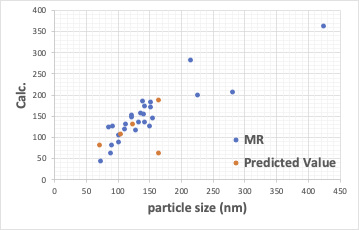
塗料の解析例3
この例もDICの特許になる。(JPA 2017-031336)
特許の目的は、「優れた塗膜外観と高い帯電防止性とを両立した硬化塗膜を形成できる活性エネルギー線硬化性組成物 」を得ることになる。
しかし、有機溶剤の含有率を高くすると、金属酸化物粒子の分散状態が変化する。そして凝集を生じることで、硬化塗膜の白化し、その表面抵抗値が上昇する問題がある。
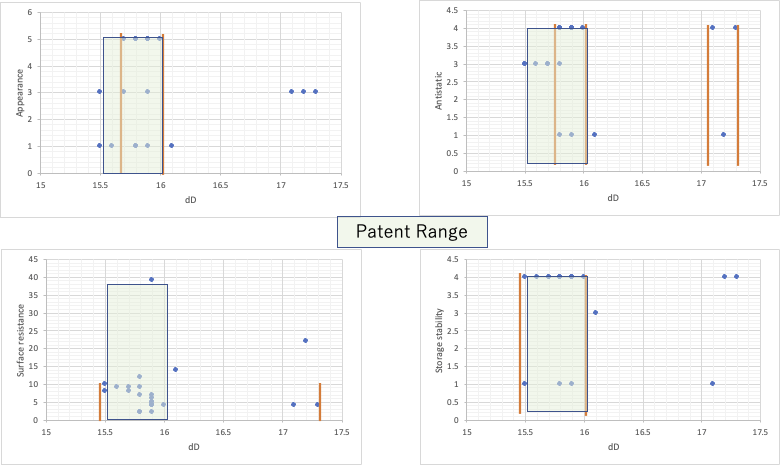
分散項 (δD)が15.6~16.1MPa^0.5 の範囲に入る。
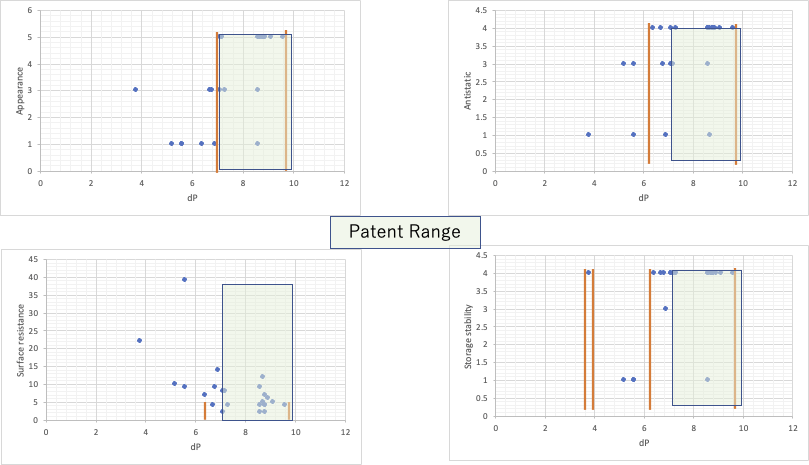
分極項(δP)が7.2~9 .8MPa^0.5 の範囲に入る。
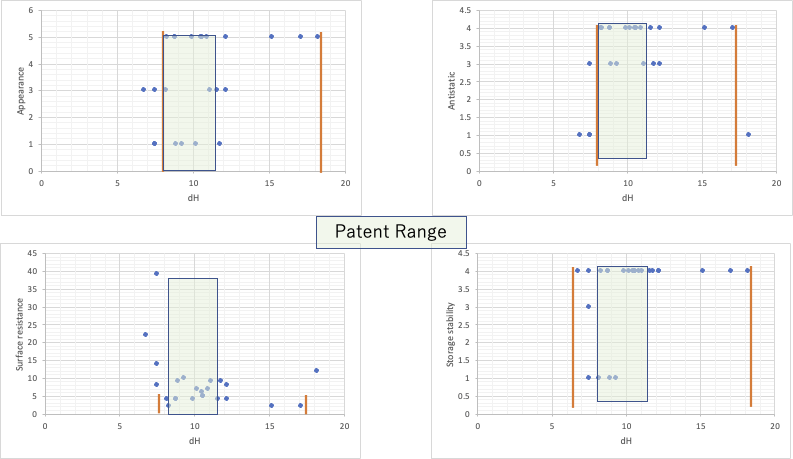
水素結合項(δH)が8.2~11.4MPa^0.5の 範囲に入る。
そのような有機溶剤を含有することを特徴とするとクレームされている。
実際に行った実験をまとめると次のようになる。
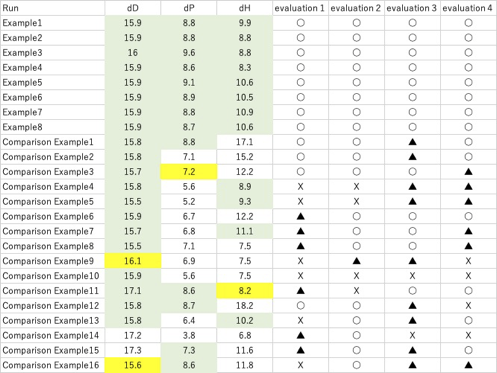
緑色にマークした部分は、特許請求の範囲に入る。黄色でマークしたところは限界値である。範囲を外れるものは色をつけていない。
このようなハンセンの溶解度パラメータ(HSP)の範囲で規定した特許は非常に多い。しかし、4つの評価結果とHSPの各成分を図示すると次のようにとてもわかりにくなる。
dD figure
dP figure
dH figure
そこで、特許のクレームとしては、4つとも評価が◯の物の範囲を規定しただけになる。
特許は作成した者以外には見通しの悪いものであったほうが好ましい。
そこでHSPの各成分を3次元空間にプロットして眺めてみよう。
Web app Sphere Viewer
Drag=回転, Drag+Shift キー=拡大、縮小, Drag+コマンドキーかAltキー=移動。
半透明の緑色の球がハンセンの溶解球と呼ばれるものだ。
マウスでドラッグして、位置関係を確認しよう。
赤で示してある球は4つとも評価が◯の溶媒である。
青で示してある球は評価が悪い溶媒である。
そして、ハンセンの溶解度法の言い方では次のようになる。
「ハンセンの溶解球に入ってくる(混合)溶媒は評価が高い(◯が4つ)」
ハンセンの溶解球の中心は[dD,dP,dH]=[15.9, 8.9, 9.8]で半径は2.0である。
特許のクレームだと、範囲は立方体になるので、少し範囲が広くなる。
この方法は優れた方法で、他社の参入を予防できると考えられがちである。
しかし、分極項(δP)が9 .8MPa^0.5 以上の溶媒では試していないことがプロットしてみるとわかる。
HSPiPとMIRAI解析ツールは車の両輪のような関係である。
MIRAIで解析すると、さらに色々なことがわかってくる。
もう少し深く解析してみよう。
クレームに使われている溶媒のHSPは単独溶媒のものでは無く混合溶媒のものだ。
実際の特許では、様々な溶媒が組み合わされ使われている。そして、その混合溶媒のHSPの範囲で特許がクレームされている。
元のテーブルをまとめると次のようになる。
最後の2つの実験を予測データとする。
目的変数は、物性値のうちの4つを使う。特に帯電防止能力と表面抵抗は重要である。
次に、MIRAI用には溶媒をグループに分ける。
このグループ分けは、化学者の腕の見せ所である。
溶媒の官能基だけでなく、使われている量などからもグループ分けを判断する。
- アルコール・グループ
- エステル、エーテル・グループ
- ケトン・グループ
- その他
帯電防止能力を通常の重回帰法で解析した係数と、MIRAIで解析した係数をテーブルに含めてある。
グラフからわかるように、通常の重回帰法であっても、式を構築するのに使った溶媒の再現性はそれなりに高い。
予測用化合物の計算値が、6を超えるが、このようなランクの評価では4以上であれば問題ない。
帯電防止能
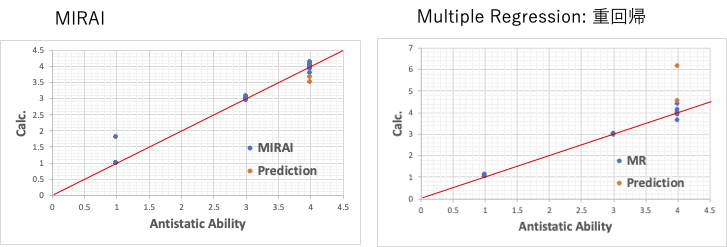
それに対して、MIRAIの解析結果では、評価値が1のものを1.79と評価している。
これは、実験CE12はCE1と溶媒組成が非常に似ているにも関わらず、評価が大きく異なることに起因する。
表面抵抗
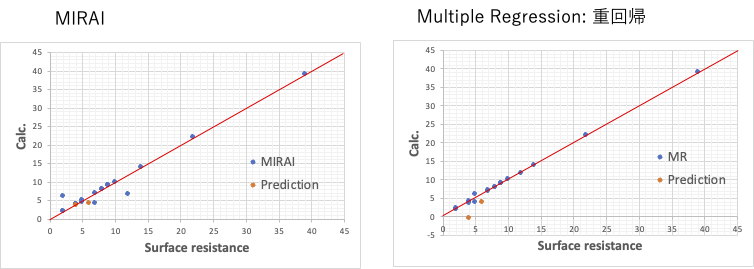
同様に表面抵抗でも、RIRAIでは外れる実験が2つある。これもCE12とCE1である。
通常の重回帰解析では、項目間に相互作用があるもの、項目に非線形性があるものには使えない。そのような系の解析にはMIRAIが適している。
この系は、重回帰解析で十分と言えるのだろうか?
非常に良くある大きな間違い。

例えば、CE10は全ての評価値がXである。これをベースにして、重回帰係数から評価が高くなるように処方を検討してみよう。
S1-1の溶媒,0.67gを0gにして、その分S1-2溶媒を増やしてみよう。
| Properties | Exp. | CE10 -MR | New Comp. -MR | CE10-MIRAI | New Comp. -MIRAI |
|---|---|---|---|---|---|
| Antistatic | 1 | 1 | 579.36 | 0.99 | 0.94 |
| Surface resistance | 39 | 39 | -1092.72 | 39.04 | 40.05 |
| Appearance | 1.0 | 1 | -22.07 | 1.0 | 0.97 |
| Storage stability | 1.0 | 1 | 1.0 | 1.02 | 0.27 |
| 物性値 | 実験値 | CE10の組成重回帰 | 新組成重回帰 | CE10の組成MIRAI | 新組成MIRAI |
|---|---|---|---|---|---|
| 帯電防止 | 1 | 1 | 579.36 | 0.99 | 0.94 |
| 表面抵抗 | 39 | 39 | -1092.72 | 39.04 | 40.05 |
| 外観 | 1.0 | 1 | -22.07 | 1.0 | 0.97 |
| 保存安定性 | 1.0 | 1 | 1.0 | 1.02 | 0.27 |
組成をほんの少し変えただけで、重回帰法では結果が500倍、しかも、プラスマイナスに変動してしまう。
ニューラルネットワーク法では、こうした過学習の問題はよく知られている。
重回帰解析でも、重回帰係数が非常に大きな±の値で構成されているときに、こうした変動が起こる。
私は統計に詳しいわけではない。もしかしたら、統計的には、この結果を使うなと言ってくれるのかもしれない。重回帰解析が使えないなら、処方開発をどうしろというのか? 統計はこの問題に対して何をしてくれるのか?
新たにLASSDGEプログラムを作った。これは相関係数と回帰係数の最適化まで行う。ニューラルネットワーク法、PLS法、PCA法なんでも良いから処方開発に適したツールが欲しい。もしかしたら、探し方が悪いので、そのようなツールはすでにあるのかもしれない。もしご存知なら教えていただきたい。
統計は得意ではないが、プログラミングは得意なので、自分用に作ったのがMIRAI解析ツールである。
CE10の組成を少し変えても、結果は大きく変化はしていない。一つだけ実験値1を0.27と予測しているが、結果がXのものが1なので、1以下は全てXとなるので問題ない。
Copyright pirika.com since 1999-
Mail: yamahiroXpirika.com (Xを@に置き換えてください) メールの件名は[pirika]で始めてください。