
2018.8.25
情報化学+教育 > MAGICIAN 養成講座 > 講義資料 > 第2回 データ収集、データ処理
MAGICIAN(MAterials Genome/Informatics and Chemo-Informatics Associate Networks)
MAGICIANとは、材料ゲノム(Materials Genome)、材料情報学(Materials Informatics)、情報化学(Chemo-Informatics)を結びつけて(Associate)ネットワーク(Networks)を構築していかれる人財です。
第1回でも触れたように、実験結果を統計解析して、その予測式をもとに材料の研究開発を進める事は、3-40年前から普通に行われていた事です。
その際には今と違ってビッグデータが必要などとは言いませんでした。
データが1点では何もわかりません。
2点あればだいたいの傾向がわかります。
3点あれば誤差も含めて傾向がはっきりしてきます。
大事なのはある現象に対してどれだけ、「知識と経験に基づいた合理的な式が立てられたか」でしょう。
それを知識も経験もないAIにやらせようとしたら、良いもの、悪いものを大量に教えるしかありません。
良いものだけを教えたら、当然、悪くなることを理解できないAIになります。
実験のうち99%は役に立たないデータしか取れず、特許や論文に残っているものはせいぜい1%の成功例でしょう。
AIにはそれをバランスよく教えないといけません。
最先端の話ではなく、2−30年前には普通に行われていた温故知新の技術では、データをどう集めたか、その集めたデータをどう処理したかを再確認しておきましょう。
データマイニング
マイニングというのは、探鉱(有意義な鉱石を土の中から発掘する)のことです。
そこでデータマイニングというのは、膨大なテキスト、画像の中から、有意義なデータを探し出すことです。
最近ビッグデータ、ビッグデータと騒がしいですが、そこでのデータは有意義なデータを指しているようです。
しかし、データマイニングの本質は、本当に役に立たないカス・データと、有意義なデータを差別化するのに必要なダメ・データを区別して収集することでしょう。
エジソンは、「私は1つも失敗した事がない。うまくいかないケースを幾多となく発見しただけだ」とか言ったそうです。
そうしたものをペアで持つ事が大事になります。
昔何かで読んだのだが、面白い実験があった。
例えばある文章がある。
その中からランダムに文字を虫食いにする。何%虫食いになったら意味が通じなくなるかを作者ごとに調べていた。
確か筒井康隆と小林秀雄を比較していたと記憶しているが、かたや30%虫食いでも意味が通じるのに対し、もう一方は5%で意味が通じなくなる。
デジタル時代どちらが有用な情報源かといえば当然、30%虫食いでも意味が通じる方でしょう。
OCR(光学文字認識)と言っても完全ではありません。
文字の大きさがマチマチ、縦書き、横書き、アルファベットとギリシャ文字、数字が混在する化学系の論文、特許をAI搭載のOCRソフトに読ませたところで、認識率は95%を越えるのも大変でしょう。
そうした不完全なデータからでは、AIが知識を獲得するのは非常に困難となります。
それに対して人間の脳は非常に曖昧にデータマイニングする機能を持っています。
下の文章をさーっと流し読みしてみましょう。
「みさなん、まだまださむいすでが、おんげきですか。かぜなどひていないいですか。」
ほとんど違和感なく意味がつかめると思います。
Typoglycemiaとは、単語を構成する文字を並べ替えても、最初と最後の文字が合っていれば読めてしまう現象のことです。
脳のこの機能の為に、文章はいくら推敲しても直せないものは直せないことになります。
(最近のWordなどは自動で赤い波線を引いてくれますが、修正候補は出てきません)
当然検索しても探せない文章になってしまいますが、人間が読めば意味の通じる文章になります。
こうしたことから、これから先は、e-実験ノートなどを導入して失敗例も含めて情報を蓄積していこうという一つの流れがあります。それはそれで正しいと思います。
そして、過去については手書きの文章は無理でも、印刷されたものは(精度は低いかもしれませんが)デジタル化してテキストデータマイニングしよう。
過去のグラフなどをデジタル化して画像認識しよう。
などと言う議論に繋がっていくのでしょう。
その際に、現在のAIが成功しつつある、自然言語解析、画像認識がビッグデータ解析によって行われているので、材料開発もビッグデータが必要と誤解しているように思えます。
いくら材料系論文、特許解釈用のAIを開発したところで、人間の脳には叶いません。
それなら人間の手間のかかる部分だけをアシストするソフトを開発して、解釈は人間が行うしかないと私は思います。
テキストデータマイニング
今更,筆者が言うまでも無いことですが、Googleの検索はテキストデータマイニングの最高峰に位置しています。
例えば、”燃料電池 触媒”と入れて検索すれば、”fuel cell”と英語表記のページも検索に引っかかってきます。
Typoglycemiaでわざと”feul cell”と入れて検索しても、自動的に”fuel cell”の結果を表示してしまいます。
それならば、わざわざテキストデータマイニングのソフトを開発しなくても、Googleの検索を社内用のサーバーにも適用すれば良いだけのことです。
(事実そのようなサーバーが販売されています)
法人向けGoogle Appsを利用するのが一番簡単でしょう。
PDFのファイルをOCRする機能も、Google ドライブには搭載されています。
筆者のような個人ユーザーでは使えるような値段ではありませんけど。
幸い、筆者はMacユーザなので、昔から(Apple Sherlock:1998年)ファイル内の単語まで検索できました。現在700冊の専門書、PDF,特許(36044件、23GB)がMacのハードディスクに溜め込まれています。
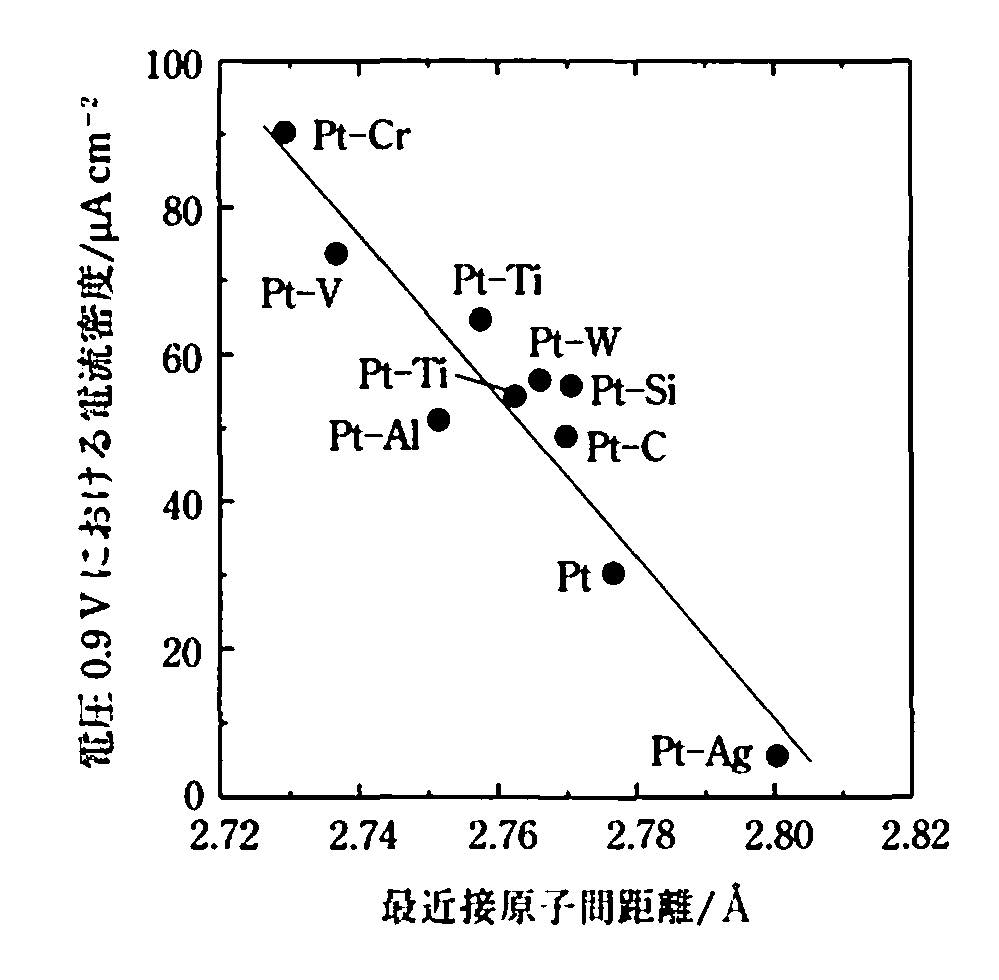
ファイルはOCRされているので,”燃料電池 触媒”と検索すると,1054件ヒットします。その中で,科学マスター講座 触媒化学 丸善出版(2011)に,白金と卑金属との合金でさらなる高活性化が図られているとありました。
元文献:
V. Jalan et al., J.Electrochem. Soc., 130,2299(1983)
書籍にはグラフは記載されてますがテーブルはありません。そこでグラフをデジタル化する必要があります。
画像データマイニング
例えば上図のようなグラフがあった時にデジタイザーを使って数値を拾うことは,昔はよくやられていました。
様々な計測装置はペンでアナログなチャートを残すだけでしたからデジタイザーは必須でした。
民生用のハードウエアー・デジタイザーは1983年Apple II用が初めてだそうです。
その後,マッキントッシュになってからは,すぐにソフトウエアー・デジタイザーがあったと記憶しています。
と言うことは,筆者はもう30年近くこうしたグラフから数値を起こして利用してきたことになります。
マック用で筆者が愛用しているのは,GraphClickというフリーウエアーです。
様々なタイプの画像を読み込み,フレームとスケールを設定した後,拡大鏡を使いながら読み取り点をクリックして行くとデータがデジタルで得られます。
非常に優れたソフトですが,ついに開発は止まってしまいました。
また、最新のMacでは動作しなくなりました。(32bitコードが混在するため)
授業の際には,学生はほとんどWindowsなので,Windows用のデジタイザー・ソフトを探してもらっています。
毎年ちゃんと見つけられているようなので,Windows版にも優れたフリーウエアーがあるのでしょう。
それでは,こうしたソフトの,AI自動化はどうでしょうか?
論文とか特許からグラフを探してきてグラフをテーブル化できるでしょうか?
このくらいシンプルなグラフならどうにかなるかもしれませんが,Pt-Tiに横棒が入っているのをちゃんと理解できるかは疑問です?
混み合った領域で、どの点がどれだかちゃんと認識できるでしょうか?
複数のスレッドが存在する場合、マーカーが重なっているのが理解できるでしょうか?
フレームの一部を省略する2重波線などを理解できるでしょうか?
などなど問題は多いように思えます。
また、このくらい鮮明な画像であれば誤認識は少ないでしょうが、TiとTlなどはOCRでの誤認識が多いです。
C5H11(シクロペンチル基)なども、正式に下付きの数字にした、C5H11を使っていると、CsH11と、C5がCs(セシウム)になったりします。
実は、このグラフにはPt-Tiは2回出て来ます。
Tlの誤植かも知れません。
でも同じように作ってもこのぐらいの誤差が出る可能性もあります。
Tiにはαとβフォームがあるからです。
人間の実験者であれば、最低そのぐらいは考えるでしょうが、AIに自動的に行わせた場合、どこまでを期待するか?は難しい問題になります。なんせ、AIには常識はありませんから。
結局ある程度まではソフトウエアーが行い,詰めのところでは人間が対話型で処理しなければならないのでは無いでしょうか。
その対話を通じて成長できるようなAIであれば、教えれば教える程、人間は楽になって行くのでしょう。
しかし、AIがその特徴の高速性を発揮して、対話が何時までも律速になるのなら人間の方がソフトの奴隷になるのだと思います。
おそらく、コンピュータやAIに適したデータはあくまでもテーブル・データなのでしょう。
人間の脳と言う低速で曖昧なプロセッサーでも直感的に理解できるようにグラフ化された段階で、情報は縮退されてしまっています。
そこから情報を引き出すためには、修士のレベルの専門性、常識を理解し、直感を持ったAIが必要になります。
当分の間は人間が関与しなければならないのであれば、テキストデータマイニングの段階で、重要な論文、特許を優先していくという判別が重要となります。
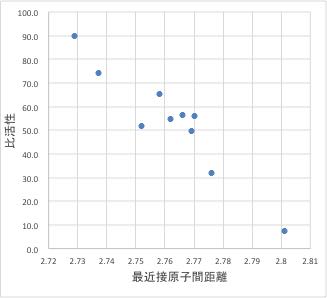
ここでは取りあえず、人力でデジタル化したグラフデータを解析する事を考えてみましょう。もとの図と比べて、ほぼ問題のない精度でデジタル化できていると言えるでしょう。
識別子(Descriptor)の収集
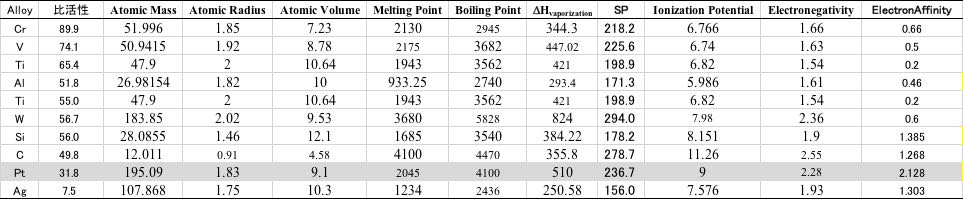
Pt合金の比活性は最近接原子間距離でほぼ決まる事がグラフから読み取れます。
それでは、このグラフに無い原子との合金の比活性はどのように予測できるでしょうか?
片端から合金を作成し、X線などを用いて原子間距離を測定し、最適合金の種類と配合比を決めていけば良いでしょう。
そうした実験手法をHTP(High ThroughPut)法といい、それはそれで合理的な実験手法です。
それに対して、原子の持つ化学的な情報から、絞り込んで行くのがChemo-Informatics(化学情報学)的なやり方です。
マテリアル・ゲノムやMI(material informatics)はこちらの手法をとります。
それを行うには、原子の持つ化学的な情報、識別子(Descriptor)を収集していきます。
例えば、フリーウエアーのPeriodic Table of the ElementsというJavascriptのプログラムは周期律表の原子をクリックすると様々な原子情報を与えてくれます。(6年ぐらい前にダウンロードして使っているが、オリジナルをネットで探しても出てきません。こうした所は困ったものです。)

化学便覧や化学データハンドブックI無機・分析編にも重要なデータが記載されています。こうした情報を比活性のテーブルに加えて行きます。
この部分の自動化についてはどうでしょうか?
単純な原子については100種類程度しか存在しないので、ある程度は自動化も可能でしょう。
そして、比活性と相関の高い識別子を絞り込んでいきます。
テーブル中のSPというのはSolubility Parameter(溶解度パラメータ)という物性値で、蒸発潜熱を体積で割った値を、ルートを取ったものになります。
物質の相溶性などの指標として重要な値です。
多くの場合、一つの識別子とだけで比活性と高い相関(単相関)が得られる事はありません。
特に炭素(C)は金属では無いので識別子の値が異常値を取ります。
そうした時には複数の識別子を使って重相関を検討します。
複数の識別子から有用な識別子を選択して重相関式を作るには、変数選択重回帰法を使います。
ソフトとしては、大学の授業の初回に配布しているYMSBを利用します。
使い方は授業の際に徹底的にやっているのでわかるでしょう。
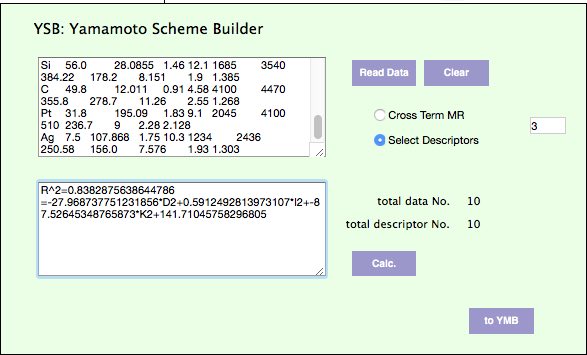
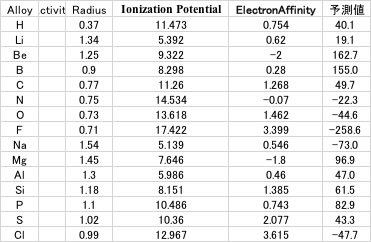
先ほど作った比活性のテーブルをコピーして、データを読み込み、識別子を3つ選択し、比活性を予測する式を作成してみます。
比活性= -27.969*Atomic Radius + 0.5912*SP -87.5264*electron negativity + 141.7104
となりました。結果をグラフで表示すると下図のようになります。
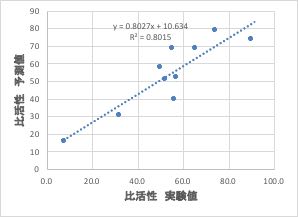
YSBプログラムは、あくまでも”相関係数が高くなるように” 3つの変数を選択するだけです。
YSBが化学的に意味のない変数を選択していたら、いくら相関係数が高くても予測性能は出ません。
そこで化学者のカンと経験で、その列を取り除いて、変数選択を繰り返す事になります。
こうした解析を繰り返しても相関係数が高くならないこともあります。
次にやる事
相関係数が高くならない場合には次のことを考えます。
- 入力ミスは無いか?
- 識別子として足りないものは無いか?
- 現象として、非線形現象では無いか?
多くの場合、1.が原因で精度がでません。
Typoglycemiaの効果で、何度見直しても入力ミスは見つからないので苦労します。
2.の識別子として足りないものを考える時には、プラスに一番大きく外れるものと、マイナスに一番大きく外れるものをマークして、その違いを説明する因子を考えます。
YSBが作った式で、プラスに外れるものは、Ti, マイナスに外れる物はCrでした。
TiはElectron Affinityがこの中で一番小さいです。
また、Crについては遷移金属の中ではAtomic Radiusが一番小さいです。
そうした識別子を必ず入れるとしたら他の識別子はどれを選べば良いか?
このテーブルには無い、他の識別子は無いかなどを考えます。
3.の非線形性を考えるのは最後の段階です。この程度のデータ数ではニューラルネットワーク法を用いるのは意味がありません。
各項目のlogを取ったり、ルートを取ったり、クロスタームを考えたり徐々に非線形性を上げていきます。
最終的にはどんな式になったでしょうか?
自分考えた比活性の予測式を書き出してみましょう。
比活性=
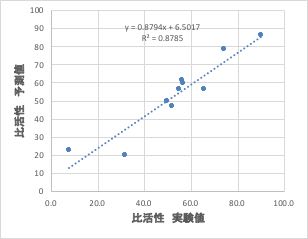
筆者の作った比活性の予測値を実験値に対してプロットすると上図のようになります。
YSBが自動的に選択した識別子と比べ、特に高活性の領域での精度が高くなっていることが分かると思います。それは漫然と計算したらそうなったのではありません。
ここは非常に大事な点で、例え、推算精度(相関係数)が劣っていても、自分が検討したい領域(今回は高活性な領域)で精度が出る式が、目的に対して、よりベターな予測式であることを忘れてはいけません。
なんでも、かんでもニューラルネットワークに放り込めば、全領域でぴったり合う予測式が作成され、新しい合金触媒が設計される事を期待するのであれば、マテリアル・インフォマティクスに手を出すのはお勧めしません。
化学情報学は意外と地道な作業の積み重ねになります。
YSBの選んだ識別子はとても参考になります。
変数が3つ以上になると線形で考えても訳がわからなくなります。
また項目間の単純な相互作用を見つけるクロスターム重回帰法も搭載されているので、多くの場合シンプルでかつ強力な解析結果を手に入れることができます。
こうしたYSBによるアシストを受けながら、材料設計を行なった場合、出来上がった予測式は、作成した人間に強く依存してしまいます。
偉そうな事を言っても、触媒設計など一度もやったことのない身としては、結果がどのくらい妥当なのかは判断できません。
予測結果の検証
まず、自分で作成した予測式を使って、周期律表の原子全てに対して、比活性を予測してみましょう。
ここから先は、学生によって答えは、まちまちになります。
筆者が作成した予測式で説明しますが、答えが異なっていても一向に構いません。
そして、比活性の高い順にソートをかけて、高活性になる原子を特定しましょう。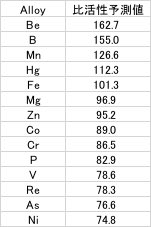
さて、比活性が高くなる原子種は特定されましたが、如何せん研究室を持たない非常勤講師の筆者では実験による検証は行えません。
そこで書籍、ネット上にある情報から検証を行ってみます。
このグラフを取り出した書籍には次のように記載されています。
「白金を卑金属と合金化して高活性化することは,リン酸形燃料電池(PAFC)の実用化過程で活発に研究された。チタン,クロム,鉄,コバルト,ニッケルなどと合金化することにより,最大で3倍程度の活性増大が得られている.」
比活性の高いと予測した、Cr, Vはもともとグラフに記載されていました。
Fe, Co, Niは書籍に記載されていました。
HgやAsは毒性の観点から使いたく無いので除外します。
他の原子について、“燃料電池 Pt-B 触媒”のようにGoogleで検索をかけてしまいます。
例えばホウ素の場合、トヨタ特許(WO2014034357A1 ) 酸化耐性と触媒活性とを両立する燃料電池用電極触媒 炭化ホウ素に担持された貴金属
山口大学論文、PtをMgOに担持
埼玉大学論文、PtをZnOに担持
などのように、B, Mg, Znに関してはPtの担持体として優れていることがすでに知られていました。
また、Mnに関しては、田中貴金属(Spring-8ワークショップ)Pt-Co-X 3元系合金触媒でMnが最高の性能という資料が見つかったので、Mnに関しても良い性能になることがすでに知られているようです。
そうすると、今回設計した、比活性(ただし筆者の予測式)の高い原子のほとんどは、既に知られているものであることが検証されます。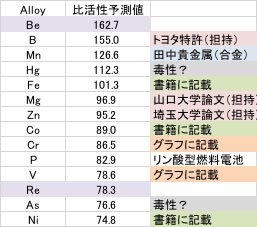
残るものは、BeとReでこれらはGoogleの検索には引っかかってきません。
原子の周期律表の位置から考えて、Beは酸化ベリリウムとしてPt担持用、Reは合金触媒用として使うのでしょう。
この二つに関して、コンピュータの計算だけで特許を書いてしまうのが材料ゲノムによる材料設計の面白さであり怖さでもあります。
論文と違って特許は正しくなくても良いのです。
Pt-BeO担持、Pt-Re合金は性能が高い(可能性がある)。
そんな特許が認められる時代になってしまった事が、materials informatics時代の一番の問題で、(それの善し悪しはおいておいて)どう対応すれば良いのか? を問われています。
識別子、遺伝子
ここで、(私が)使った触媒としての遺伝子は、
原子半径
イオン化エネルギー
電子親和力
の3つという事になります。
また、田中貴金属のPt-Co-Xという3元系の触媒のデータから、3元系の触媒に関して最適なものをマテリアル・ゲノムで探してしまう事も可能でしょう。
学生が作成した予測式で、これ以外の原子は出てきたでしょうか?
そうした触媒系はネットで見つかったでしょうか?
大学での研究はともかく、企業の研究であれば、こうしたマテリアル・ゲノムの開発手法を取り入れない理由は全く無いように思えます。
スパコンが必要なわけでもなく、学生が個人で持っているような性能のPCで十分計算できてしまいます。
高価なソフトを導入しなければならないわけでもありません。
PDCAを非常に高速に回すことができるようになります。
(最近の授業でコンピュータを持参とアナウンスすると、iPhoneではダメですか?という学生が出てきました。彼らはiPhoneで修論を書くのでしょうか?)
新たな実験結果、参照論文、競合他社から出た特許などから新たな情報が得られたら、即座に予測式を立て直すフットワークの軽さが成功を左右するようになります。
例えば、BeやReを試して、結果が悪かった場合、すぐに予測式を作り直します。
もしくは、諦めずに実験のやり方を変えるなど様々な対策が取れるようになるはずです。
日本でのこうした研究が進まなくても、海外では当たり前のように使われ出しています。
待ってはくれません。日本の論文、特許がmaterials genomeの検証に使われる、3元系への拡張に使われる。
「そんな時代への対応が十分か」が問われ出しているのです。
大学での教育
マテリアル・ゲノムが有効だと言っても、今回示したように、化学者としての地力の高さも必要な事も指摘しました。
それでは企業はともかく、大学ではどういう教育によって学生の地力を高めたら良いのでしょうか?
実は、ここで取り上げたグラフと同じものが、2001年に発行の、化学総説49、新型電池の材料化学という書籍中でも使われています。
そこでは、分子軌道法を使った反応機構が説明されています。
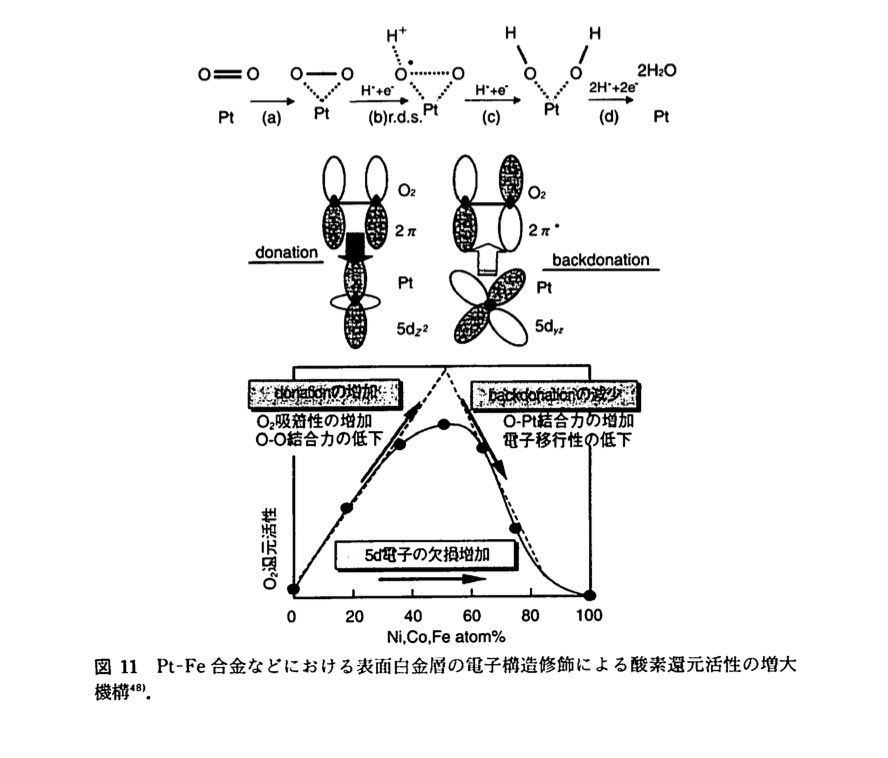
これを見たときに、酸素のπ軌道と白金のd軌道の反応である事を理解して、塗りつぶされた原子軌道の違いを学生が理解できるかどうかは重要な教育上の問題として残っています。
それでは、どんな原子ペアが良いのかを全て分子軌道法で遷移状態を求めて評価する事を学生に求めるのかは、意見が分かれるでしょう。
現在のところ分子軌道計算はそこまで精度は出ないように私には思えます。
最低限、電子配置とイオン化エネルギー、電気陰性度の値から、
Pt:[Xe]4f14·5d9·6s1
Ionization Potential 9eV
Electronegativity 2.28
Re:[Xe]4f14·5d5·6s2
Ionization Potential 7.88eV
Electronegativity 1.9
である事を理解し、
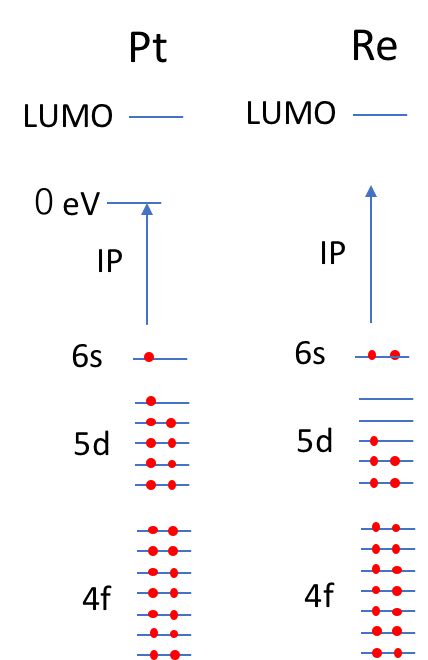
電子配置の図を頭に思い浮かべられる必要はあると思いますが。。。
また、電荷平衡法による、原子上の電荷が次のように求められる事を知っていることは重要でしょう。

今回の触媒設計の遺伝子は、原子半径、イオン化エネルギー、電子親和力であることが示唆されましたが、この3つがわかれば、電荷平衡法で原子上の電荷が計算で出すことができます。
電荷支配の反応なら、この3つの情報が必要十分条件である可能性が高くなります。
そうしたことを理解できるように学生を育成することは、教育機関としての大学の役目であるように思えます。
その上で、実験結果の無い系について予測して可能性を示唆できるなら、高度な地力を持った学生として、AIアシストを受けながら将来にわたって生き延びられる人材になることができると言えるので無いかと思います。
雑感
自分が住んでいる次元の、下の次元は理解できるけど、同次元やそれ以上の次元は脳には理解できないのかもしれません。
人間の住んでいる次元が、3次元なのか、時間軸が4次元目の軸なのかで、2次元グラフしか理解できない、3次元グラフまで理解できるかの差はあるかもしれません。
程度の差はあれ4次元以上のグラフは人間にはお手上げでしょう。
かと言って一旦縮退させてしまった情報は復元できません。
どのようにしてAIにデータマイニングさせたらいいかは、難しい問題として残ります。
しかも解析までAIに任せるなら、失敗データをどう収集させたらいいのかは答えが出ません。
そのあたりの解決は数学者や哲学者に任せるしか無いように思えます。
大学でこうした授業を取り入れてしまうと、実は評価の際に困ったことが起きます。
どんな予測式であれ、それを評価の高低には結び付けられないからです。精度が低くても、たまたま性能の良い合金触媒になっているかもしれないし、その逆もあるかもしれません。
運も実力のうちなので、授業にちゃんと参加していれば皆高い点数を差し上げています。
大学の入試までは、結局は記憶力の高いものが勝ちます。
社会に出てからは答えのないところで競わなくてはなりません。
答えの無いところで競うなら、地力をつけて、AIアシストをうまく利用して、目的に対して高い確率の道を選ぶことは学生のうちに身につけておいて欲しいと思います。
今回紹介した事例は、2−30年前のやり方で、マテリアル・ゲノムと呼べるような代物ではありません。
分析結果も計算結果も非常に少なくても何とか方向性を見出して材料設計を行ってきた古き良き時代の研究手法です。
でも技術の進歩によって、そうした研究も、とても楽に結果が出せるようになってきたと思います。
データ収集に関しては,インターネットの進歩によって,非常に楽になった面と,マテリアル・インフォマティクスの進歩によって非常に不便になった面があります。
楽になった面はすぐにわかるでしょう。情報はPDFなどの形で容易に入手できるようになりました。
特に、引退した今では、図書館を利用できない身になってしまいました。それでもなんとやっていかれるのは、論文などをネットで収集できるからです。
マテリアル・インフォマティクスによって不便になったというのはどういう意味でしょう?
最近,特許などで顕著なのですが,MIやマテリアル・ゲノムをやっているような先端企業は,他社がデータを逆解析できないようにデータ記載を工夫するようになってしまいました。
AI教育用のデータとしては、実施例と比較例で良いものと悪いものをバランスよく教えなくてはならないのに、
案外1970-90年代の論文,特許の方がMI用のデータとして優れたものが記載されているように思えます。
情報化学+教育 > MAGICIAN 養成講座 > 講義資料 > 第2回 データ収集、データ処理
Copyright pirika.com since 1999-
Mail: yamahiroXpirika.com (Xを@に置き換えてください) メールの件名は[pirika]で始めてください。