
どこか実験できるところと組まないと、本当に終わらないかもしれない。
マイクロウエーブ をかけたときに、どこまで温度が上がるか、HSP値とQSARを使って予測するページを2010年に作っていた。
2021年、第15回日本電磁波エネルギー応用学会シンポジウム:2021年度ショートコースで、マテリアルズ・インフォマティクス(MI)を利用して、マイクロウエーブをどのくらい吸収して温度がどのくらいになるのかを予測する式を構築する方法を解説した。
2つ目のページは去年作ったものだから作り直す必要はまだないかもしれない。
2010年のページを改訂するのに、当時のデータを集め直した。
CAS#とかを集めている間に、最近稼働を始めた、MIRAI-Gに計算を放り込んだ。
入力値は溶媒の、δD, δP, δH、分子体積と沸点。
目的変数は、1分間MWを照射したときの到達温度。
この予測値が得られると、鈴木カップリング反応とかでマイクロウエーブ で反応が加速できるかの指標が簡単に得られる。
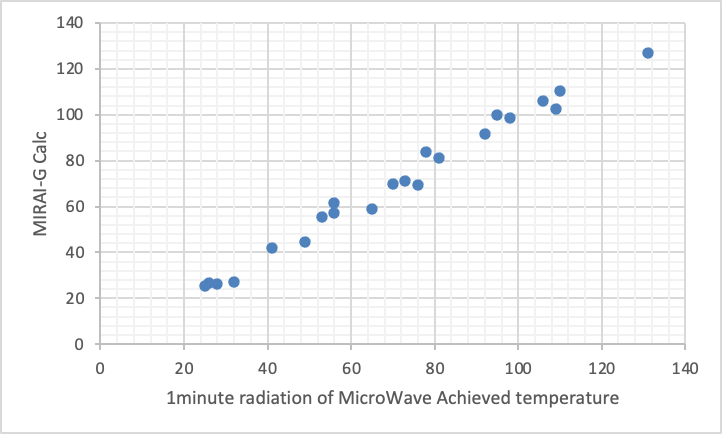
なんなんだ。この計算結果は?
1年で精度がずーっと高くなっている。
予測式をあげるから、検証実験してくれる人いないかな?
論文化とか特許作成権利もあげるから。
昔のデータをまとめ直すたびに新しい解析ツールで計算して面白い結果が出るなら、改訂は永遠に終わらないだろうな。
まー、こうして引退しても永遠に暇つぶしができるって考えれば、それもいいかもしれないけど。
HSPiPには、δD, δP, δH、分子体積と沸点を予測するY-MBが搭載されているので、SMILESの構造式があれば、到達温度予測値が得られる。
そうね。マイクロウエーブ に限らないか。
動物実験代替だろうが、薬だろうが、予測試験してくれるなら式はあげても良いかな。
うーーーーん。。。。
無理筋か。。。
生データは提供しているのだから、自社のMI/ML/AI部署に計算させれば余計な手間は無いもんな。
こっちは論文や特許が出てくるのを待てば良い。