
1998年に、物性値を複数同時に解析するニューラルネットワーク法のプログラムを作成した。
例えばハロゲン含有化合物の沸点のデータは比較的多い(1892データ)。ところが臨界温度は284データしかない。
これらの物性値を分子構造だけから推算したい。
十分な精度で推算できるなら、コンピュータ上で分子を組み立て、候補に入ったものから実際に合成を進めることができて、研究が加速される。(当時、筑波に出向して代替フロンの設計研究をやっていた。)
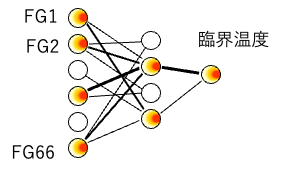
原子団が66種類定義されているが、12種類の原子団はパラメータが決められない。
臨界定数の測定は非常に困難を伴うのでこれ以上データが増える見込みもない。(高温になると分解したり、そもそも温度を安定的に制御できない)
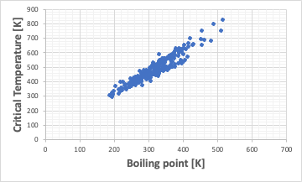
しかし、沸点と臨界温度は上図に示すように相関関係がある。
そこで、ニューラルネットワークの構造を次のように変更した。
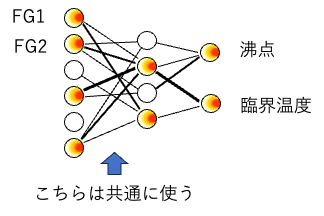
入力ニューロンと中間ニューロンの間の結合荷重は共通に使う。
元々は、出力層に2つのニューロンを配置するタイプのNNは変異原性がある、無い、燃える、燃えないなどの判別解析に使われる。
それをQSARに使う。
このような学習が成立するなら、臨界温度のデータが決まらない12種類の官能基を持つ化合物であっても、臨界点を予測することができる。
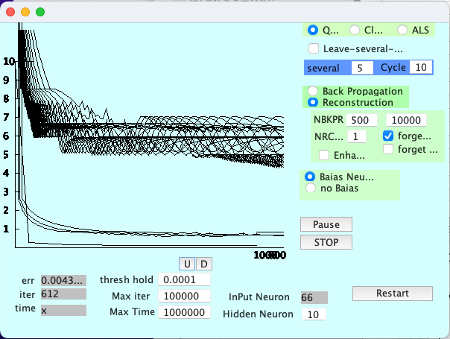
1998年に作ったJAVAのプログラムを引っ張り出してきて、走らせたところ、いまだにちゃんと動いてくれた。
20年分の新たなデータを継ぎ足し計算を行った。
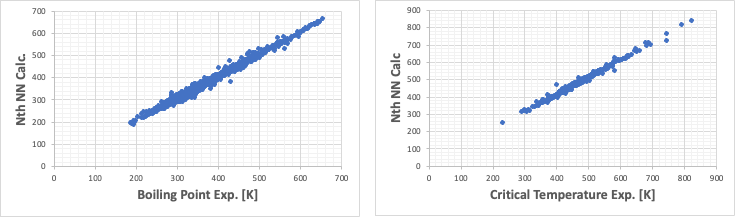
インプットが原子団でも、中間ニューロンのところでは原子団によらない粗視化が働いているのだろう。良い結果だ。
Nthは2個である必要はなく、蒸発潜熱やAntoine Bなど沸点と関連のある物性値ならなんでも使えるし、Nthが4個でも5個でも使える。
こうしたやり方は、最近では転移学習とかいうらしい。不勉強なのでどんなパッケージがそのような計算ができるのかは知らないが。
物性値が多くない場合には試してみると良いだろう。
できあいのプログラムを改造するのも簡単だ。
私は市川先生の書籍にあった、再構築学習法のプログラムをベースに改良したものを使っている。