
2019.1.23
情報化学+教育 > 情報化学 > フリー・ツールの利用 > EPA T.E.S.T.
フリーツールの利用として、EPAのTESTを紹介しましょう。
EPA(United States Environmental Protection Agency:米国環境保護庁)からT.E.S.T.というフリーウエアーが公開されています。このTESTというのは、Toxicity Estimation Software Toolの略です。
EPAのHPからWindows, MacOS, Linux版がダウンロードできるので、各自のシステムにあったものをダウンロードしましょう。
このソフトウエアーの目的は、ある化合物があった時に、そのToxicity(毒性)を予測して環境評価をできるようにしようという事です。
分子を描いて計算ボタンを押すと、毒性に関する推算を行ってくれます。推算結果はHTMLの形で出力されるのブラウザーで簡単に確認できます。
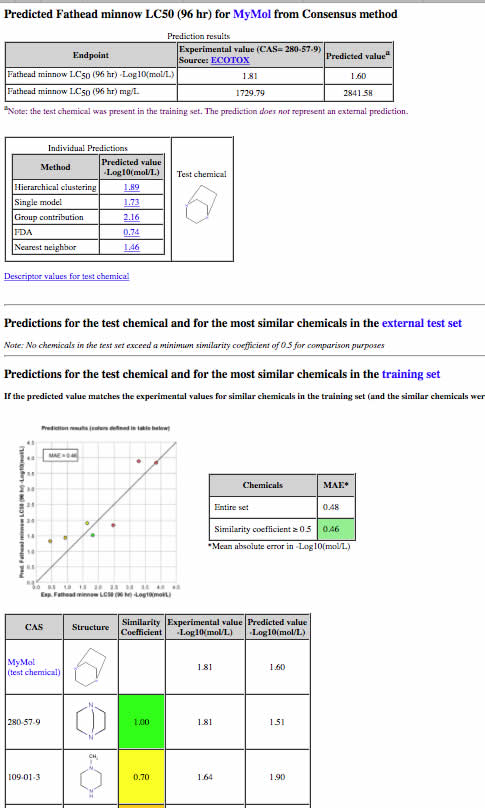
その出力中に、識別子のリストもあります。(2d_descriptors.txt)
これはRDKitのようなトポロジカルな指標や官能基の数など、797個の識別子が出力されます。
| Descriptor | Value |
|---|---|
| x0 | 5.39734123 |
| x1 | 3.94948974 |
| x2 | 3.46410162 |
| xp3 | 2.94948974 |
| xp4 | 2.28023897 |
| xp5 | 2 |
| xp6 | 0.70710678 |
| xp7 | 0.25 |
| xp8 | 0 |
| xp9 | 0 |
| xp10 | 0 |
| xc3 | 0.40824829 |
| xc4 | 0 |
| xpc4 | 0.8660254 |
| xch3 | 0 |
| xch4 | 0 |
| xch5 | 0 |
| xch6 | 0.25 |
| xch7 | 0 |
| xch8 | 0 |
| xch9 | 0 |
| xch10 | 0 |
| knotp | -0.45777711 |
| xv0 | 5.13706788 |
| xv1 | 3.3973666 |
| xv2 | 2.68328157 |
| xvp3 | 2.1973666 |
| xvp4 | 1.51934853 |
| xvp5 | 1.2 |
| xvp6 | 0.42426407 |
全てはペーストしていませんが上のようなDescriptorが手に入ります。
QSAR(定量的構造活性相関)で毒性を扱う研究者であれば、このTESTというソフトウエアーの素晴らしさは既にご存知でしょう。
MAGICIANを目指すなら、このソフトのできる以上の事を目指して欲しいと思います。
ソフトに付属のMolecularDescriptorsGuide.pdfとTEST User’s Guide.pdfは必読でしょう。
EPAのHPにはそのソフトを作成するのに使われた物性値がsdfファイルの形でダウンロードできるようになっています。
Training and prediction sets(12 MB) used in T.E.S.T. (sdf format)
もし、やり方がわかるのであれば、TEST4_2_1の中にある、OverallSets.jarを展開してみましょう。さらに詳しいデータセットが得られます。
このsdfファイルは推算式を構築した、Trainデータと予測性能を検証する用のtestに別れています。物性の種類は次のようになっています。
- 96-hour fathead minnow 50 percent lethal concentration (LC50)
- 48-hour daphnia magna 50 percent lethal concentration (LC50)
- Tetrahymena pyriformis 50 percent growth inhibition concentration (IGC50)
- Oral rat 50 percent lethal dose (LD50)
- Bioconcentration Factor (BCF) The bioconcentration factor data set was compiled by researchers at the Mario Negri Istituto Di Ricerche Farmacologiche
- Developmental Toxicity (DevTox)
- Ames Mutagenicity (Mutagenicity)
- Normal boiling point
- Flash point
- Surface tension @25
- Viscosity @25C
- Density
- Water solubility @25C
- Thermal conductivity @25C
- Vapor pressure @25C
- Melting Point
まず最初にやることは、このsdfファイルをテーブルに変換する事でしょう。
詳しいやり方はこちらで説明しています。
問題はこのsdfファイルにはSMILESの構造式が入っていない事です。
そこで、まずsdfファイルをテーブルに変換して、その中のCAS番号からSMILESを検索して埋めていきましょう。
検索には次のようなページを使えば良いです。
PubChem Identifier Exchange Service
というのがあって、CAS番号、PubChem CID, InChis, Smilesなどの分子を特定するIdentifierを他のものに一括変換できます。
変換スピードが早いのが特徴です。
CTS, The Chemical Translation Service:
このページも化合物の名称などから、様々な分子のIdentifierへ変換してくれます。
対応するフォーマットが広いのはいいですが、変換は遅いです。
MAGICIAN養成講座用](/Education/JP/MAGICIAN/index.html)には、ファイル分割のPro版を提供しています。
これは、OpenBabelを使ってmolファイルからSMILESへ変換します。
| Train | Test | |
|---|---|---|
| BCF | 541 | 135 |
| BoilingPoint | 4607 | 1151 |
| Density | 7125 | 1783 |
| DevTox | 227 | 58 |
| Flash Point | 6690 | 1672 |
| IGC50 | 1434 | 358 |
| LC50 | 659 | 164 |
| LC50DM | 283 | 70 |
| LD50 | 5931 | 1482 |
| Melting Point | 7509 | 1875 |
| Mutagenicity | 4591 | 1147 |
| Surface Tension | 1133 | 283 |
| Thermal Conductivity | 352 | 90 |
| Viscosity | 444 | 113 |
| Vapor Pressure | 2006 | 504 |
| Splubility to Water | 4016 | 1004 |
まとめてみると上記のようなデータ・セットになります。
このデータを元にRDKitを使って識別子を発生させ、PLS, PCAを使って予測式を作り、TESTデータの予測性能を検証します。
ここまでは、MAGICIAN養成講座用のProツールを使えば、半日仕事で終わるでしょう。
最低限ここまでは自分でやってみましょう。
以下は、私がやった結果となります。
大事なのは、この計算は誰がやっても同じ結果になるという事です。
化学の知識があろうが、無かろうが、院生だろうが、大学生であろうが、高校生であろうが同じ結果になります。
これができたところで、EPAに自分の作った予測式をT.E.S.T.に載せてくださいと言っても無理な話でしょう。
それは、ニューラルネットワークを使った機械学習でやったとしても同じでダメでしょう。
既に誰かがやっているに決まっています。
PLS計算のNP値を増やせば少しは改善するでしょう。
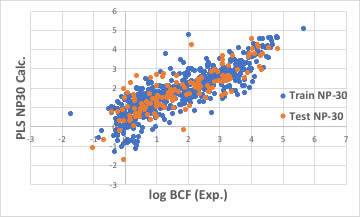
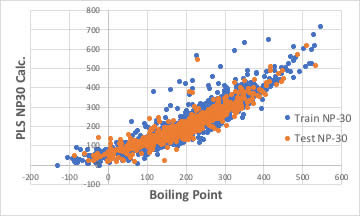
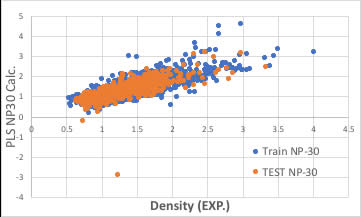
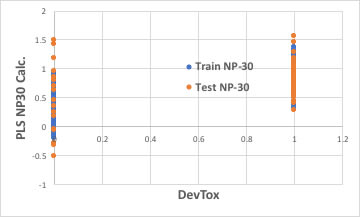
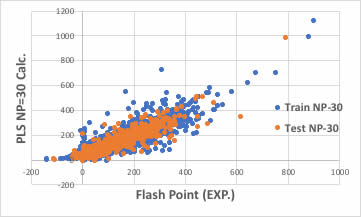
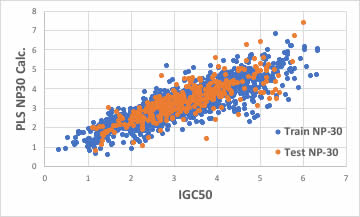
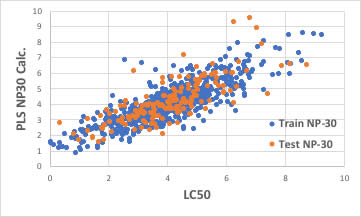
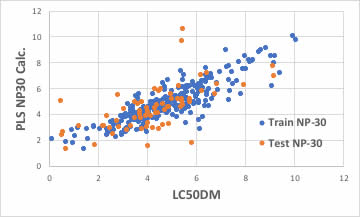
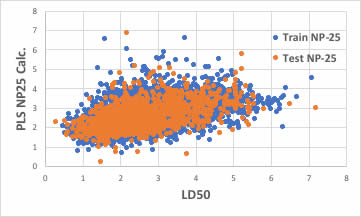
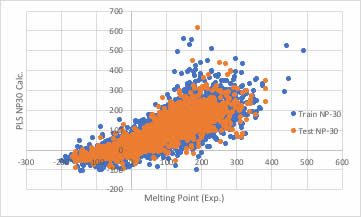
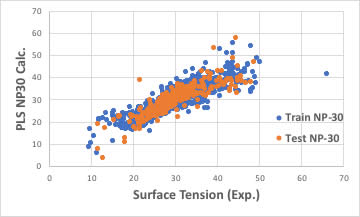
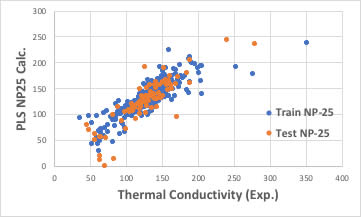
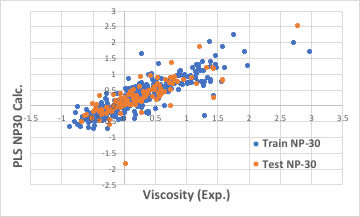
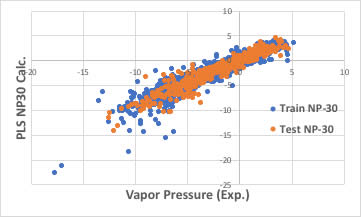
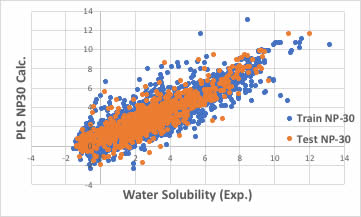
識別子の数を増やせば良いかもしれません。
ブラウザー版のRDKitは117識別子だが、EPAのT.E.S.T.は797識別子、Mordredは1000を超え、Dragonは6000以上の識別子を発生します。
人工知能(AI)は知能などないから、一杯識別子を食わせれば、収束するモデルを見つけてくれるかもしれません。
データ数が138個だった時には、水への溶解度は以下のようにモデル化できました。
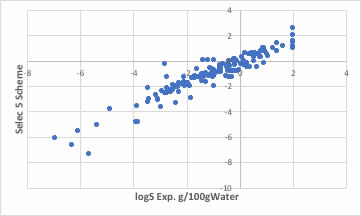
データ数が1000個を超えると次のようになりました。
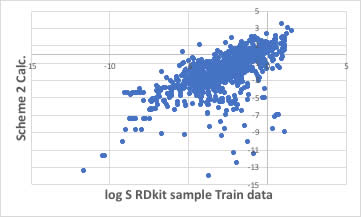
少ないデータで予測式を作って、データ数がどんと増えたら、本当に正しく推算できるでしょうか?
データ数が138個で作ったScheme(2)で1000個を計算してみると次のようになりました。
全く性能が出ていないことがわかります。
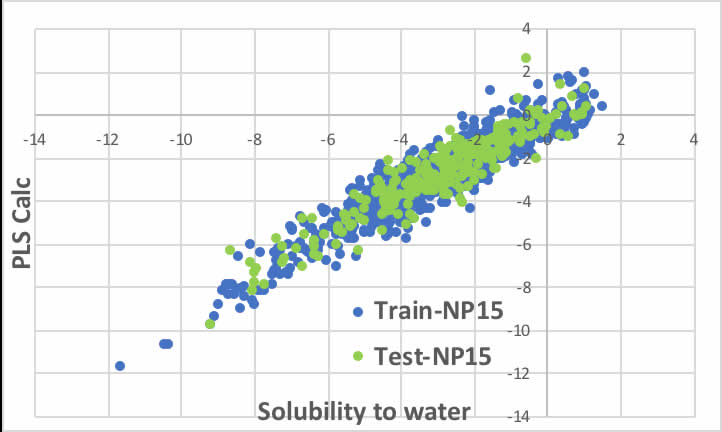
今回は4000データ以上になり、以下のようになりました。
Trainデータですら十分に収束しないのであるから、1000データで作った予測式を使っても予測性能は全くでないと考えられます。
(単位系をmol/Lからg/100ccへ変換してあります。)
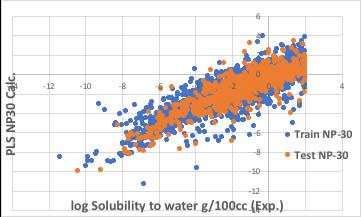
1目盛りは2であることを考えてください。1目盛り違えば、logで言えば100倍溶解度が異なります。
2目盛り違えば10000倍溶解度が異なります。
統計上の決定係数 R^2 が幾つだから良いモデルだとか、そんな話ではありません。
データセットが大きくなった時には、小さいデータセットで作った式は使い物になりません。
ということは、推算と言ってもそれが合うのは内挿の時だけであり、外挿の時には使えないことになります。
ということは、情報科学は常に実験科学の後追いで、推算式を構築すること自体無意味なことになります。
画像解析のように1000万の画像を見せて猫を認識させたように、1000万の化合物を見せて、識別子を10000作って学習させれば正しく溶解性を答えられるようになるか?
アルファ・ゼロのようにコンピュータ中で自己対戦して賢くさせることができるか?
ネット上の文章を片っ端から入力して自然言語解析させたように、ネット上の化合物の情報を片っ端から学ばせれば良いか?
そう思うのであれば、この分野でできることは無いので誰かがやってくれるのを待てば良いだけです。

「ビックデータを出してくれれば、計算できます」と言うのは一休さんの虎退治と同じこと。
100万の画像に含まれる動物の種類が幾つあるか想像してみましょう。
化合物はCAS番号のついたものだけでも3000万種類はあります。
合わないものが出たら識別子を増やしを繰り返したところで、いつまでたっても終わりはありません。
EPAのT.E.S.T.の発想はそれとは全く逆の発想に基づいています。
私もマテリアル・ゲノムのページで指摘したように、「ドローンのような小型の、用途に特化したマイクロ・セルAIを多数構築する」がこれからの主戦場になると考えています。
その際には、化学の知識を総動員しなければならなくなるでしょう。
MAGICIANにはやれることがたくさん残っています。
今回ここで、ゼロベースでできあがったものを、どう改良してEPAに提示できるぐらいの式を構築していくか?
まずは自分で考えてみましょう。
大学で、「考えてみよう」と言うと、「わかりません」「全て覚えますので答えを教えてください」と言う学生が圧倒的に多いです。
いつまでも受験戦争の時の考えを引きずるのか?
それで済むなら私も人間に教えるよりはAIに教えます。
以降のページは自分なりの推算式改良の答えを持ってきたMAGICIAN養成講座の生徒だけにリンク先を教えましょう。
このページを作ってから2年経ちましたが、リアクションは日本からはゼロでした。
それらのページも、あくまでも私の解釈で真実ではありません。
EPAのTESTの中にはlogKow(オクタノール/水分配比率)がありません。
何か理由があるのでしょうか?
情報化学+教育 > 情報化学 > フリー・ツールの利用 > EPA T.E.S.T.
Copyright pirika.com since 1999-
Mail: yamahiroXpirika.com (Xを@に置き換えてください) メールの件名は[pirika]で始めてください。