
2018.8.22
情報化学+教育 > MAGICIAN 養成講座 > 講義資料 > 第1回イントロダクション
MAGICIAN(MAterials Genome/Informatics and Chemo-Informatics Associate Networks)
MAGICIANとは、材料ゲノム(Materials Genome)、材料情報学(Materials Informatics)、情報化学(Chemo-Informatics)を結びつけて(Associate)ネットワーク(Networks)を構築していかれる人財です。
2015年6月15日の日本経済新聞に“米,「材料ゲノム」の衝撃”と言う記事が載りました。
オーダーメイドの医薬品の開発の際に,患者の遺伝子解析を行って薬を設計する。
同じように材料もゲノム解析して設計してしまおうと言う発想です。
筆者は1997年頃から,ニューラルネットワークを使った“物性推算と逆設計”を行ってきたので,特に目新しい記事ではありませんでした。
しかし,ここに来て様々な団体が人工知能(AI)と材料設計を結びつけるプラットフォームなどを立ち上げているので,“むやみやたらとAIを恐れるな,でも簡単な話なので無視はするな”と言う話を書いておこうと思います。
ちなみに,友人のKevin (Joback法の物性推算で著名)にゲノム,ゲノムと言っても通じず,スペルを書いたらそれは”ジーノム“と言わなければ通じないと笑われました。
日経新聞の要旨
最新の情報科学を駆使して,優れた性能を持つ新材料の開発速度をこれまでの2倍に高めよう。
そんなプロジェクト,「マテリアル(材料)ゲノム計画」が2011年アメリカで始まり,中国でも似たプロジェクトが立ち上がった。
材料のデータや論文のデータベースを人工知能が学習して,職人の技の本質を理解して材料を設計する。
実験など一度もしなくても,情報科学の手法だけから競争相手の企業と同じ材料にたどり着けた。
日本の産業競争力を維持するためにも,危機感を持って取り組むべきだ。
という論旨です。
(こうした論旨を捉えるのはAIには難しいらしいが,私は何点もらえるでしょうか?)
参入の障壁
私は化学系の研究者なので身びいきはあるにしても,日本の産業競争力の根幹は素材・材料だと思います。
しかし,こうした材料設計は、筆者が大学生に教えている程度のことを理解できれば,簡単に行うことができます。
学力の差による参入の障壁は大きくありません。
アイデア勝負のところが大きいです。
「日本人は英語の論文は読めるが,外国人は日本語の論文は読めない」などと言う障壁も、Google Translateで、今はほとんどなくなってきています。
高価なスパコンやソフトが必要なわけでも無く,誰でも気軽に材料設計をすることができます。
現在のスマホの計算能力は20年前のスパコンより早くなっています。
ネットワークも格段に早くなり,情報はネットの上にあふれています。
誰でも簡単にマテリアル・ゲノムを始められる環境にあると言うことです。
10年以上前の資料ですが,日本は年33万件特許を無料公開し,中国からは17,000件/日,韓国からは55,000件/日アクセスがあるといいます。
日本も昔はさんざっぱら欧米の特許、論文を読んで、追い付け追い越せしてきたのだから文句は言えないでしょう。
しかし、単に特許を読んでトレースするのと、AIを使った情報解析の差は認識しておくべきでしょう。
ノウハウとして隠しておいたことが解析によって明らかになり、逆に特許を握られることも起こり得ます。
以前なら大企業同士の争いの特許紛争がAI時代には当然変わってきます。
一度も合成したこともない会社が特許の根幹を握ることもあり得ます。
AIが学習するにはビッグデータが必要という間違った参入障壁が言われています。
ビッグデータをもつ、GAFA: Google, Amazon, Facebook, Appleなどがイニシアチブをとり、少ないデータしか持たないなら参入は無理だと言われているようです。
Googleは1千万枚の画像を見せてニューラルネットワークに学習させたところ、猫の写真を認識できるようになったといいます。
でも、うちの子供は図鑑2-3冊で、猫ぐらい認識できるようになりました。
自然言語認識、画像認識でビッグデータが必要なのは、AIのレベルが低いだけのことであって、参入障壁にはなりません。
全てのマテリアルに適用できる汎用化学系AIならともかく、特定のマテリアルに限った限定AIならデータ数は少なくても十分参入は可能でしょう。
今やらなくてはならないのは、ドローンのような小型の、用途に特化したマイクロ・セルAIを多数構築する事だと思います。
サイズが小さくなればビッグデータはいりません。
その道のプロの化学者が、教え方を学び、教材を用意して、準備ができたところから飛び立てば良いだけです。
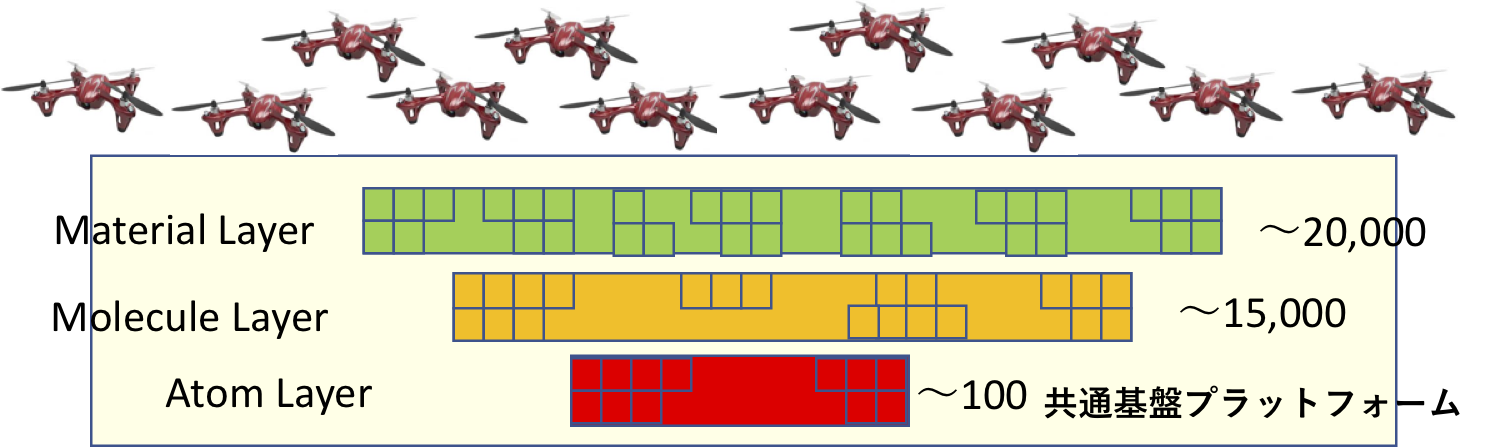
大学での授業
大学での授業は2019年で9年目になります。
以前はトピックス(トヨタが燃料電池自動車を売り出した、オリンピックの開催が決まった、など)に合わせて,「我々化学系にできる事」を授業で取り上げて来ました。
ここ数年は,「AI-ロボティクス時代を乗り切り,後40年間職を失わないためには今何をしておかなくてはならないか?」を教えています。
キーワードは,「AIアシストを受けた化学系研究者」になるためには? です。
電動アシスト自転車は漕ぐ力の半分をアシストしてくれます。漕ぐ力がゼロならアシスト力もゼロになります。なんでもかんでもAIがやってくれるなら,自分を磨くというモチベーションが無くなってしまいますが、化学系ではそうはなりにくいです。
同じAIを使っても、AIに何を、どう教えたかでAIの答えも変わってくるからです。
結局、地力の高い学生が生き残るのでしょう。
知識量だけでいえば、とっくの昔、グーグル先生に我々教師の側もかないません。
知識を教えるだけの教師は早晩需要はなくなるでしょう。
事実、最近の予備校でのネット授業では、解答を間違えると、似たような問題を集中的に解かせて、弱点を克服させるAIが活躍していると聞きます。
ネットに溢れる知識を全てAIに学ばせたらば、AIの答えは同じになってしまうのではないかと思われるかもしれません。
電気・電子のデバイス設計、回路設計のような物理法則に基づくもの、将棋や囲碁のようにルールが明確で、勝ち負けがはっきりしているものは徐々にそうなって行くだろうと思います。
しかし、化学は勝ち負けがつかないことが多いのです。
硬いポリマーと柔らかいポリマーのどちらが勝ちですか?と聞かれても「用途次第です」としか答えようがありません。
そこで、誰が、何を、どう教えたのかによってAIの答えてくれるレベルは千差万別になります。
人間としての大事な特徴として、「臨機応変に変化できること」が挙げられます。
化学系のAIに対して、教育係はどう教えれば良いかを試行錯誤していくのです。
自動化の波が追いつく頃には、それまでに教育したAIを組み合わせて「臨機応変に」次のレベルのAIを組み上げていくのです。
「自ら変化し続けられる」ことを売り物にできない学生も(さしあたっては売り手市場であるらしいですが)早晩需要はなくなるでしょう。
最近更新をサボっているが、大学での講義内容はMOOCのページを参照してください。
化学とボードゲームの違い
AIが人間を超える技術的特異点(シンギュラリティ)を、囲碁や将棋の棋士たちは2017年に経験しました。
後20年や30年は人間が勝つだろうと言われていたのに、あっという間に追い抜かれてしまいました。
「AIによってなくなる仕事」などが色々言われていますが、「仕事を取るのはいいけど、ホビーを取るな!」と言いたいのは私だけでしょうか?
これまで、囲碁や将棋でAIが勝つのが難しかったのは、ビッグ・データが無かったのがその一因でしょう。
石や駒を打つ様々な局面に対して、名人だったらどう打つかのデータが圧倒的に足りないので、AIへの教育がうまくいきませんでした。
転機はある程度、能力が高くなり、後は自己対戦で延々とビッグデータを増やすことができた事だと思います。
勝ち負けがはっきりしているのでそれが可能でした。
では、ある化合物の毒性(薬効)を予測するシステムを作ることを考えてみましょう。
毒性(薬効)が既知な化合物はせいぜい数千化合物もありません。
それをAIに教育しても、圧倒的にデータが足りない事になります。
自己対戦させると言っても、どちらの毒性(薬効)予測システムが勝ったのか、負けたのかは実際にその化合物が作られて評価されてないとわかりません。
コンビ・ケムを使ってハイ・スループットで合成評価する試みが進んでいますが、ボードゲームの自己対戦と比べ、高速化は非常にしにくいのです。
また、ボードゲームは、大きくはチェス、囲碁、将棋、オセロぐらいですが、化学は、例えばCAS番号が付いている化合物は3000万種、工業的に生産されている化合物10万種、年間1000トン以上生産されているものは5000種と非常にバリエーションが広いのです。
このバリエーションの広さが、一般化の難しさ、ひいては1つ1つの材に対する少ないデータ数になり、AIによる解析が進まない原因となるのでしょう。
いわゆる計算機科学との関係
筆者がニューラルネットワーク法(NN法)を始めた1997年の頃から、NN法の問題点として、計算に時間がかかる、メモリーを大量に使う、質の高い学習データを大量に必要とするという問題がありました。
20年たち、CPUはどんどん高速化し、メモリー、ハードディスクは潤沢になりましたが、質の高い大量データが必要なのは相変わらず変わっていません。
そこで利用されたのが、分子軌道計算(MO計算)や分子動力学(MD計算)などの計算結果などです。
分子軌道計算は、とりあえずは、分子の構造さえあれば計算できます。
すると、分子体積、分子表面積、電荷、ダイポールモーメント、HOMO, LUMO, 生成熱などの計算結果が得られます。
こうした計算結果を使って“水増しした”ビッグデータをNNの入力に併用することは昔から普通にやっていました。
ただ,そうした計算結果を用いたとしても,例えば分子の沸点や臨界温度を精度よく推算できるようにはなりませんでした。
AIに教えられる化学の知識がまだまだ足りないのでしょう。
真空中の1分子を、分子集合体にしようとした時に、液体の誘電率与えて計算することがよく行われますが、液体の誘電率を構造のみから予測することすら非常に難しいのです。
ダイポールモーメントの値も、実測値と分子軌道計算値は大きく異なるものも多くあります。
最近流行りのMI(Material Informatics)もベースの部分はMO, MD計算である事が多いようです。
どんなものも計算できるので、ビッグデータは得やすいのですが、原子が集まって分子になって、分子が集まってマテリアルになるというほど簡単な話ではありません。
ただし、計算機科学も利用できるに越したことはありません。(高校生にもできるブラウザーで分子軌道計算のページも作ってみました。)
下図は、カルフォニア工科大学のGoddard教授の作成した、Multiscale Computational Hierarchyの図です。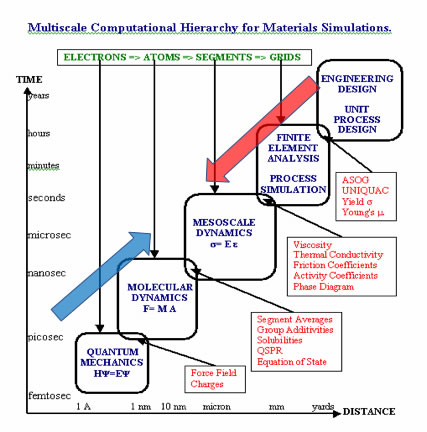
大元の図は30年以上前に作られたものですが、このバージョンは20年ぐらい前のものでしょう。
Goddard教授が日本の計算機科学に与えた影響は非常に大きいものがありました。
日本の計算機科学関連の国家プロジェクトも、このMultiscale Computational Hierarchyを基礎においているものがあるくらいです。
Multiscale Computational Hierarchy
私は、Goddard教授のところに、1990-1991年の1年3ヶ月留学させて頂き、計算機科学を学んだ経験を持ちます(1997-8年にも3カ月ほど受け入れて頂きました)。
高分子合成の実験系の化学者だけどプログラムをつくるのが大好きなので、とても有意義な留学生活を送ることができました。
図中の赤い矢印と青い矢印は私が書き加えたものです。
原子、分子、メソスコピック領域へとGoddard先生は進んで行こうとしておられたのですが、実験系の自分は実際のマテリアルを分割してメソスコピック領域へというコンセプトでした。
そうした自分の影響はGoddard教授も色濃く受け入れてくださっていて、ASOG法(日大の栃木先生が行なっていた気液平衡の推算法:Analytical Solution of Group)がUNIFACではなく記載されている。
Activity Coefficients, Group Additivities, Solubility, QSPRなどは私が得意とするところとして、図中に記載されています。
Genome解析
ゲノム解析とは遺伝子解析の事です。
最新のオーダーメイド医薬の開発では、各人の(とは言っても金持ちだけ?)遺伝子を解析して、個々人の遺伝子的になりやすい病気を特定して予防薬を投与するとか、遺伝子から特定される特異的に良く効く薬を開発するとかが行われています。
この発想と同じように材料を遺伝子に見立てて“適者生存の法則”を使って用途に適合した材料を作り出すやり方が、遺伝的アルゴリズム法というやり方です(第7回で詳しく説明します)。
別に最近出てきた新しい方法でもなく、2000年頃から普通に使われているやり方です。
ちなみに、東大の建築科を卒業の女優、菊川怜さんの卒論のテーマは、遺伝的アルゴリズムを使ったコンクリート配合の最適化だったそうです。
この方法を簡単に説明するならば,競馬のサラブレッドをどう育てるかと同じです。
素人考えで恐縮ですが,例えば競走馬の強さが,足が強い,心臓が強い(酸素を効率的に血流に乗せて送れる),肺が強い(酸素吸収能力が高い)の3点であったとしましょう。
強さを表す遺伝子がどれかがわからなくても,実際にレースをして勝った馬だけが子孫を残していけば良いのです。
徐々にレースに勝つ馬が“適者生存の法則”によって遺伝子を残し,生き残っていきます。
牛乳をいっぱい出す牛,収穫の多く美味しいお米を作る稲など原理は皆同じでです。
最近面白い話を読みました。アフリカ象は大きな牙を持つのが特徴なのに、地域によってはメスの98%が牙を失ったといいます。
これは密漁によって牙を持つ像は淘汰され、牙を持たない象が子孫を残した結果だといいます。
たかだか100年ぐらいで適者だけが生き残るので、コンピュータの中で高速に回せばそれなりに素早く解にたどり着けます。
化学の場合の素材に関しては,どういう物性を持つものを“適者”と呼ぶか,それが難しいところでもあり,非常に面白いところでもあり,化学者のセンスが問われるところです。
競馬のレースのように簡単に勝ち負けが決まらないところは,ボードゲームとの違いのようでもあります。
本来は、遺伝子はビット(0,1の数列)で表しますが、あまり数学にこだわらなくても、それなりに最適値探索は可能であるようです。
悩むよりはコードを書いたほうが早いでしょう。ここでコードを書くとかいうと、化学系の研究者はちょっと引いてしまうかもしれません。
遺伝的アルゴリズムのアルゴリズムとは何かというと、“考え方“と理解すれば良いです。
あくまでも考え方を示しているだけで、ニューラル・ネットワーク法のように汎用のパッケージソフトがあるわけではありません。
現象ごとに遺伝子の形が異なり、最適と呼ぶ性質も異なる。
最適な交叉や突然変異の起こし方も現象ごとに異なる。
そこで基本形はあるにしても細部は自分で作り込んでいかなくてはなりません。
逆にプログラムの専門家であっても、化学のことを分かっていないなら、遺伝的アルゴリズムを正しく動作させることはできません。
それにコードを書くと言っても、非常に簡単なコードなので、ぜひトライしてもらえればと思います。
講義では表計算ソフトの上に簡便的なGAのシートを作成して、動作原理を習得しています。
行った操作をマクロに記録して自動化まで行います。
大事なポイントは、遺伝子の定義の仕方と、遺伝子の“適者”の評価の仕方だけでしょう。
総当たり法
ガラス、合金や触媒など組成を自由に取れる材料を開発する場合には、遺伝的アルゴリズム法は有効です。
しかし、低分子の設計程度あれば、全ての分子をコンピューター上で組んで計算してしまうのも一つの手です。
例えばフロン代替化合物の設計では、炭素の基本骨格に対して、水素をフッ素や塩素に変換して全ての構造を自動的に発生させることを行いました。
そして物性を予測して、欲しい範囲に入った場合に候補化合物として出力させれば良いのです。
1999年当時、そうした方法でフロン代替化合物をスクリーニングしたところ、当時使っていた400Mbyteのハードディスクが、炭素数が7まで行ったところで溢れてしまい、炭素数は6までに制限しました。
今であれば、オンメモリーでも十分計算できます。
ただし、最近、200万化合物を計算し、結果をエクセルに貼り付けようとしたら、200万行はできませんでした。
ファイルを分割してしまうと、物性値をソートして、良いものを抽出するのは今でも結構大変でした。
正確に言うと総当たり法はマテリアル・ゲノムには該当しないかもしれません。
しかし、材料設計では未だに重要なポジションだと思っているので、説明に加えたいと思います。
ビッグデータの収集
先にも述べたように、ビッグデータがマテリアル・インフォマティクスに必須とは思っていませんが、最近の自然言語解析、画像解析技術の進歩によってビッグデータも格段に得やすくなりました。
例えば、ネットに溢れる論文、特許の中から、化合物の名称や分子構造を自動で抽出して、CAS番号などに紐づけるプロジェクトなどもあると聞きます。
グラフからデータ点を抽出するくらいは、20年以上前からソフト・デジタイザーがあったし、大学の授業でもそれを利用して講義を行っています。
OCR(光学文字認識)に対して、OSR(光学構造認識)のソフトがアメリカNIHのHPにあって、PDFなどから化学構造を抽出してくれます。
そうした技術の進歩にもアンテナを高く持つことは忘れないようにしましょう。 様々な有用なフリーウエアーなどについても説明をしていこうと思います。
Python言語などを用いてネットをクローリングし欲しいデータをスクレイピングして機械学習させる。そんな書籍が去年(2018)ごろから溢れかえっているようです。
しかし本当に大変なのは、集めた後のデータのクレンジングです。
ネット上のデータは玉石混淆です。
むやみに信じると痛い目にあいます。
(逆に取り返しがつくうちに痛い目をしておいたほうが良いかもしれません。国家の威信をかけたようなプロジェクトで「間違えました」は許されないでしょうから。)
雑記
化学の世界で、工場に勤務される方が、研究所に勤務する方に言う有名な言葉があります。
「期待はするけど、当てにはしない」
まだまだ、人海戦術で突貫仕事する方が、マテリアル・ゲノムより有効な事は多いでしょう。
そう言われた時に考えて欲しい一つの有名な話があります。
「ここに、1分間で分裂・成長を繰り返すバクテリアがいます。それを1つコップに入れたところ、1時間でコップが一杯になりました。コップの半分に達した時間はいつでしょう?」
答え(▶︎をクリックして開く)
59分。自分の1/10の能力しかないと見た時に、自分が10倍の能力を獲得するのに掛かった時間で、後10年、20年は大丈夫と思うのが人間でしょう。
それでも囲碁、将棋はあっという間に追い抜かれてしまいました。
いくらAIに追い抜かれても、「囲碁将棋ならでは」の楽しみは残りますけど、製造業でAIに追い抜かれたら、「実験が趣味だから」と言っても中々認めてもらえないかもしれません。
AIアシストを受けて能力を強化した人材になるしか道は残されていないように思えます。
それに関して最近読んだ新聞記事に面白いことが書いてありました。「あなたは、アトム派? サイボーグ009派?」
アトムは人工知能を持ったロボットですが、サイボーグ009は能力を強化した人間です。
企業の経営者から見たら、化学系アトムだろうが化学系サイボーグ009だろうが成果を出してくれさえすれば良いでしょう。
大学は化学系サイボーグ009の育成を目指さなければ存在意義は無いと思いますが、最近の大学は成果直結型のPJに忙しく、育成はなおざりになっているように感じます。
先日,高校2年生の息子とAI-ロボティクス時代の職について議論しました。
これからの時代,トップ,ボトムの15%以外のボリュームゾーン70%の職はAI-ロボットが行うようになり,人間は労働から解放される時代が来る。
そうした時代に必要なのは,ベーシック・インカム(最低収入)で,その収入内で自由に暮らせば良い。
そんな記事が新聞に載っていたので,それに関する議論です。
子供に言わせれば,「そんな社会は誰も望んでいない」「自由にと言っても毎日何して暮らせばいいのか」と憤懣やるかたない様子でした。
まー,毎日俳句でも考えて暮らすとか(非常に高い確率で俳句の良し悪しを判断するのはAIでしょうけど),哲学的思索にふけるとか。
ただ,原子力もそうですが,「そんな技術は人類を幸せにはしない」と言ったところで,日本だけが止めれば済む問題でもありません。
日本が完全な鎖国をするか,「人類の幸せ」を真剣に考えてくれるAIを作るか。
星新一の世界になって来ます。
それまでは,とりあえずできることをするしかありません。筆者がこれまでに授業等で話してきたことをまとめるので、興味のある学生は参考にしてください。
計算に必要なソフトやExcelのシートは大学のメールアドレス(XXX@XX.ac.jp)を通じて連絡してもらえればダウンロードのページを案内する予定にしています。
情報化学+教育 > MAGICIAN 養成講座 > 講義資料 > 第1回イントロダクション
Copyright pirika.com since 1999-
Mail: yamahiroXpirika.com (Xを@に置き換えてください) メールの件名は[pirika]で始めてください。