
2018.9.4
情報化学+教育 > MAGICIAN 養成講座 > 講義資料 > 第4a回ポリマー・インフォマティクス用のデータベース
MAGICIAN(MAterials Genome/Informatics and Chemo-Informatics Associate Networks)
MAGICIANとは、材料ゲノム(Materials Genome)、材料情報学(Materials Informatics)、情報化学(Chemo-Informatics)を結びつけて(Associate)ネットワーク(Networks)を構築していかれる人財です。
情報化学を用いて、データを解析していると、どんどんデータが増えてきます。
また、実験化学者との協業などが増えてくると、商品名しかわからない原料やそのカタログ値などもどんどん増えてきます。
昔の様にコンピュータのHDがMbyteクラスであればどうにかなったものが、Gbyteクラスになると、どうにも整理がつかなくなってきます。
扱った記憶はあっても、様々な有用な式が、どこにあったかを思い出せなくなり、自分で自分のHP、pirika.comにアクセスして調べる始末になります。
本来データをきちんと整理して持っていたいなら、本格的なデータベースを導入して管理すべきでしょう。
しかし、それを本格的にやろうとすると、それ自体が仕事になるくらい大変なことで、片手間にできる様なことではありません。
MIをしやすい様に構造化されたデータを用意しようという動きもありますが、例えば、ガラスとポリマーを同列に構造化データにすることはできません。
化学者が専門的知識を学ぶことなく、お手軽にデータベースを使い、MIを利用して研究を加速する。そのやり方を説明してきましょう。
表計算のテーブルとDBの違い
前回、フッ素ゴムの物性について検討を行った。その際に次の様なテーブルを示しました。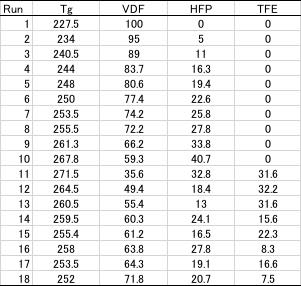
元々は表計算ソフトで作ったテーブルです。
テーブルというのは、行と列からできています。
この場合、一行目はタイトルで、二行目からは様々なフッ素ポリマーのデータになります。
列には2列目にはガラス転移温度(Tg)、その後の列にはモノマーの比率が示してあります。
1列目には、Run番号として1から順番に数字を割り当てていますが、実際にはYamamoto-20180903-1などと合成結果、分析結果と紐づけられる名称を入力する事が多いようです。
これはテーブルであって、データベースでは無い。などということはありません。これも立派なデータベースです。行の事をレコードと呼びます。そして、列の事をフィールドと呼びます。そこでこの場合は5フィールド、18レコードのデータベースと言えます。データベースをテーブル形式で表現しただけです。
さらに、合成結果のテーブルには、日付、実験のスケール、開始剤の種類、量、重合方法、重合率、反応の後処理などが記載されているかもしれません。
さらにできあがったポリマーを分析し、Tg点やそれ以外の物性値、NMRや元素分析から決定した導入モノマーの比率のテーブルがあるかもしれません。
さらに、このフッ素ポリマーを使い、カーボンブラックや受酸剤などを添加してゴムを作成し、その物性値まで含めたテーブルがあります。
ポリマーを構成するモノマーの物性値のテーブルもあるでしょう。一つの素材をMIするために、テーブルの数はどんどん増えてきます。
見通しが悪くなるので一つのテーブルにまとめようとします。
最初のテーブルに合成法や分析結果、ゴムとして処方検討した結果を列としてどんどん付け加えることになります。
テーブルはどんどん巨大化していきますが、中身はスカスカなテーブルができてきます。
コンピュータにとっては何の問題もないことですが、人間にとっては理解不能のテーブルになります。
そこで、この問題を回避するために、リレーショナル・データベース(RDB)が利用されます。
これは例えば、Yamamoto-20180903-1という一つのポリマーを表す“キー“を他のテーブルでも共通に用います。
つまり、合成テーブル、原料テーブル、分析テーブル、処方テーブル中のレコードがYamamoto-20180903-1というキーで横串が刺さった状態にしてあげます。
横串は1本である必要はありません。
モノマーはモノマーで、反応性を示すQ値、e値、沸点、密度などの熱力学的性質、毒性、環境上の指標などと横串をさしていきます。
モノマー程度の低分子であれば、キーとしてはCAS番号を使い、横串を通す事が多いようです。
そこでデータベースというのは、テーブルの集合体で、テーブル間の相対関係(リレーション)を扱いやすくしたものがリレーショナル・データベースだと思えば良いでしょう。
マイクロソフトの製品では、Excelはテーブルを扱うソフトですが、Accessはテーブルを集合体で扱うデータベース・ソフトです。
筆者は、もう30年以上マック・ユーザーなので、残念ながらAccessは使った事がありません。
クラリスワークス、アップルワークスなど、非常に優れたカード型データベースがシステムに付属していたので、それを使っていました。
現在は、それらの後継製品であるFilemaker Proを利用しています。
SQL言語を覚える事なしに手軽に使え、Excelなどとも親和性が高く、使えるコンピュータの種類も多いのが良い点です。
悪い点は、MacのOSのバージョンアップにしたがって、直ぐに動かなくなって、新しいバージョンを購入しなければならなくなる点です。 何年も使わなくてはならないDBに利用の一貫性が無いのは致命的です。 昔はソフトのアップデータで対応していたのに残念な事です。
手軽にスタートして、必要であればサーバー版など本格運用にも耐えられるシステムが提供されている。値段もリーズナブルで、個人で買える程度である。試用版がダウンロードできるので今回のサンプルを試してみて、気にいったら導入を考えてもらえればと思う。
Filemaker Proは、お勧めはしませんが、どのリレーショナル・DBでも基本は同じです。
お話程度に興味があるなら読み進めてください。
データベースの作成
今回はガスバリアー性のポリマーをターゲットに、“MIを行う為に便利なデータベース構築”を学びましょう。
まず、今回はビニル系のポリマーの酸素透過係数について解析を行います。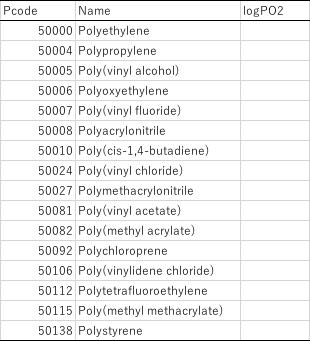
このテーブルを、表計算ソフトに打ち込んでおきましょう。
Pcodeというのはハンセンの溶解度パラメータ(HSP)を取り扱うソフトウエアー、HSPiPでつけられているポリマー用のコードです。
これをバリア1.xlsxとしてセーブしておきます。そして、Pcodeに該当するポリマーの酸素透過係数を収集します。
テーブルを作り、相当するデータを、ハンドブック、文献、データベースから収集する事は良く行う事でしょう。
これを、テーブルで扱わないで、データベースとして扱うとどんな良い事があるのでしょうか?
テーブルの読み込み
データベースをスクラッチから作成するのも良いのですが、まずは、慣れ親しんだテーブルをデータベース化してみましょう。
先ほどのExcelのテーブルをセーブしておきます。
ファイルメーカー・プロ(FMP)を立ち上げて、ファイル/開く、を選択します。(Excelのテーブルを直接FMPにドロップする事もできます)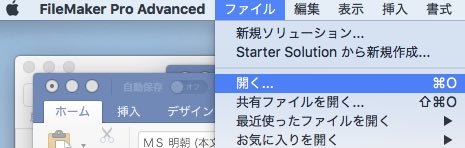
ファイルの種類を選択(Excelワークブック(.xlsx)して、ファイルを開きます。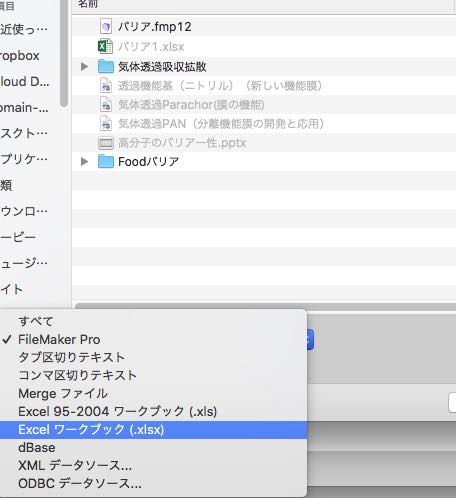
ワークシートが複数ある場合には、データベースに取り込むワークシートを指定します。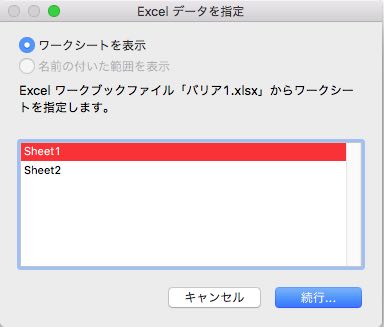
一行目はフィールド名に指定します。(フィールド名に使えない文字もあります。)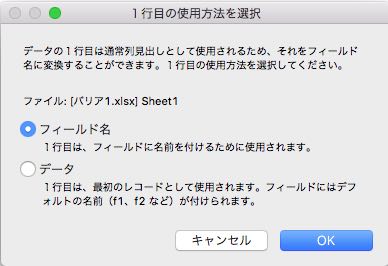
各行を取り込んだ、テーブル・レイアウトのデータベースが作成されます。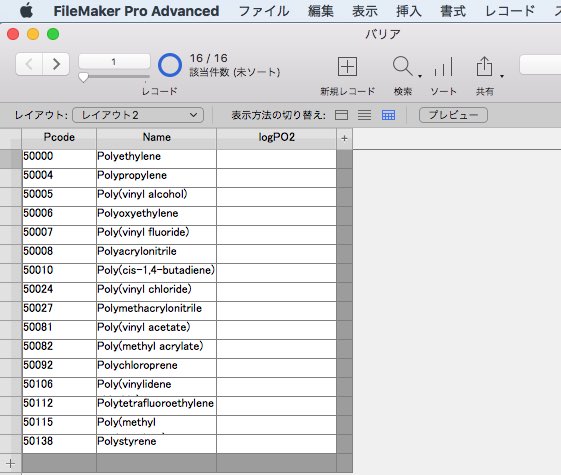
カード型のレイアウト表示。
非常に簡単に、データベース化できる事が判るでしょう。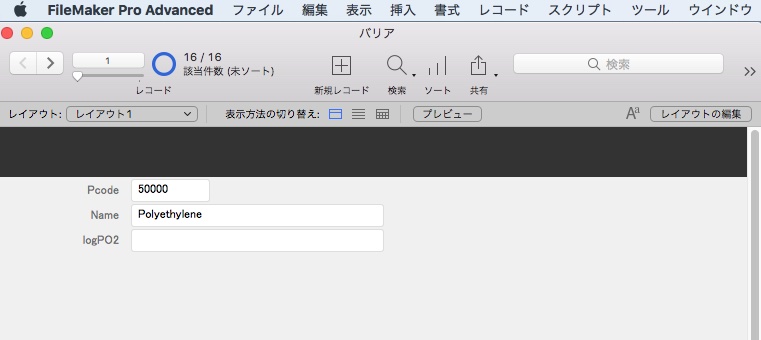
データベースを用いたデータ収集
我々、HSPの研究Grは様々なデータベース、ハンドブック、書籍、文献などからテーブルを作成し、同じようにデータベース化してあります。
(PDFからAdobeのAcrobat proを使ってExcelのテーブルを作り、FMPのファイルにしたりしています)
それらのDBと、今作成したDBを、リレーショナル機能を使って接続します。
ファイル/管理/データベースを選択します。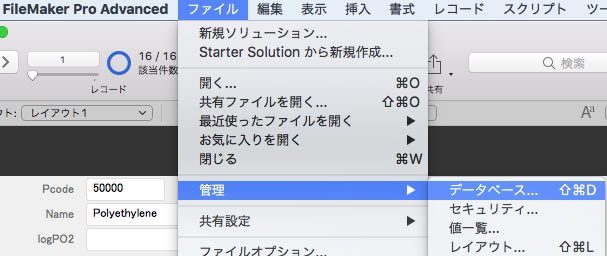
データベースの管理画面で、リレーションシップのタグを選びます。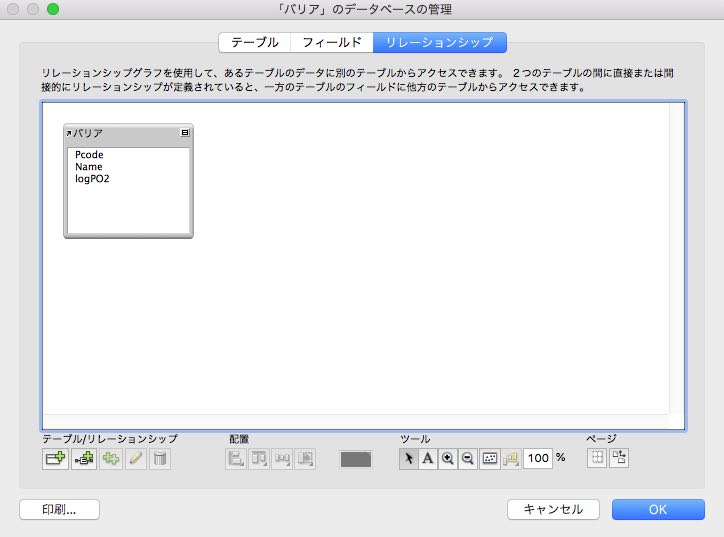
左下のアイコンからテーブルを指定します。
Filemakerデータソースの追加を行い、データベースを選択します(Brown.fmp12)。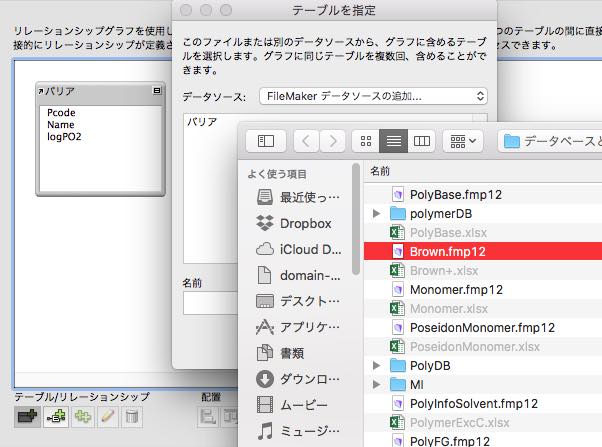
リレーションシップ編集を行い、テーブル中の共通キーを指定します。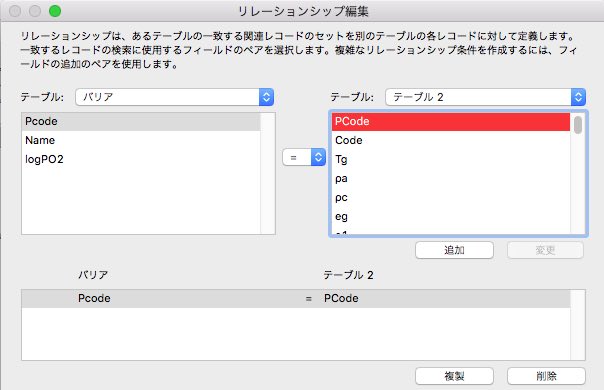
他のデータベースとも、Pcodeを用いて接続します。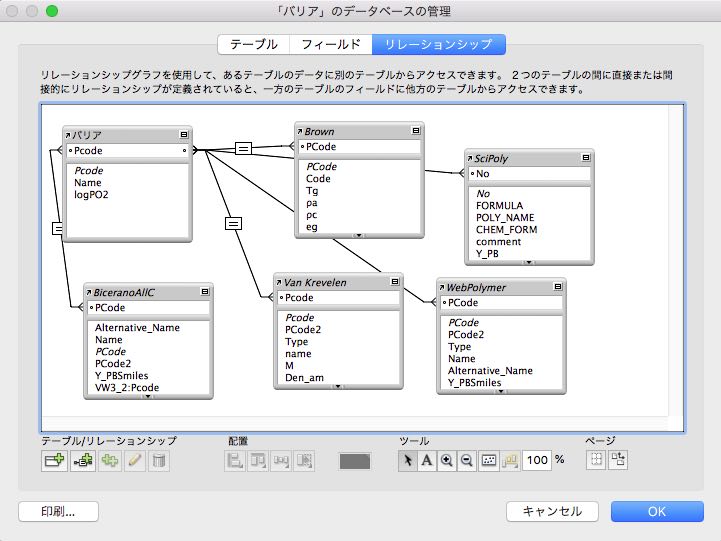
こうしたリレーショナル化が終了すると、バリアのデータベースに対して、他のDBに登録されている値を表示する事ができるようになります。
レイアウト・モードで右上のアイコンからフィールドをメイン画面にドロップします。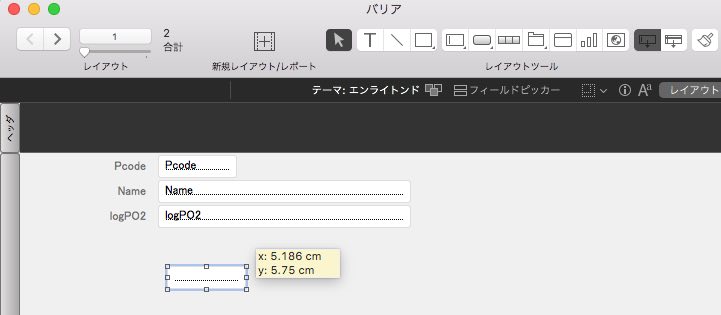
フィールドを指定します。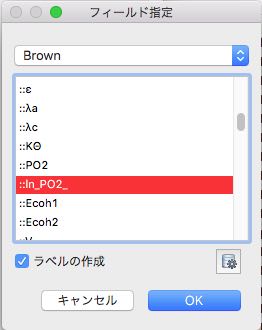
最終的に各Pcodeに対して、BrownDBとSciPolymerDBから酸素透過係数を表示できるカード型のデータベースが作成されます。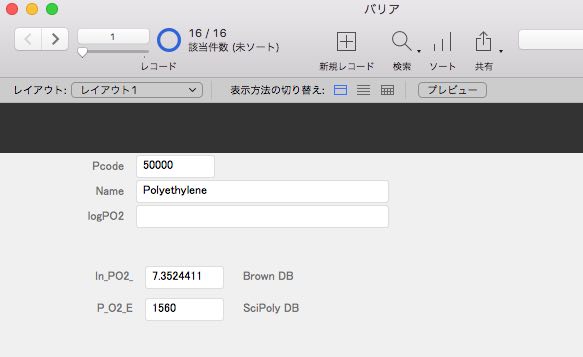
ここまでであるなら、実はテーブルに対して、各データベースを叩いて、値を持って来た方が早いでしょう。
データベース化する時のメリットは別にあります。
データベースを用いた解析
ガスバリアー性のポリマーは、例えば食品包装用の素材として非常に有望な市場を持っています。
例えば、食品用のラップ、鰹節などの匂いのきつい食材の包装材、太陽電池用のバックシート、塗料などもバリアー性が重要です。
例えば、講談社サイエンティフィク「新しい機能膜」には膜に対する透過現象に関して、次のような記載があります。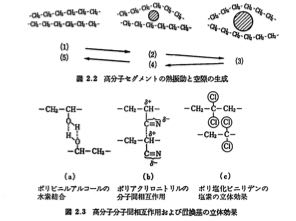
「高分子の分子間相互作用が強くなると、セグメントの熱振動がしにくくなり、膜の透過係数が小さくなる。水素結合、電荷相互作用、立体障害がその原因である。」
そして、「その分子間相互作用を定量化するのに、凝集エネルギー密度(CED)やSP値が有効である」とあります。
例えばポリアクリロニトリルは凝集エネルギー密度が非常に高く、熱をかけても溶融しません。
そして蒸し焼きにすれば炭素繊維という非常に魅力的な素材になります。
セルロース系の素材も同じように溶融しません。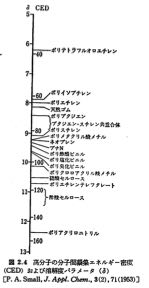
そこで、MI的な考え方に立てば、酸素の透過係数と例えばSP値を比較してみたくなります。
その時に先ほどのテーブルにSP値のデータを継ぎ足していきます。Tg点やTm点のデータを継ぎ足していきます。ポリマーを構成する原子団の情報を継ぎ足していきます。と言う作業を繰り返すか、RDBを使ってその作業を効率化するか?の選択になります。
Filemaker Proには、データベースの値をExcelの形式で書き出す機能もある。
ファイル/レコードのエクスポートを選択します。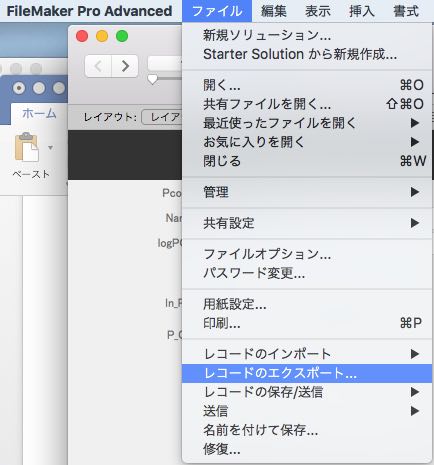
t
ファイル名とファイル形式を指定します。Excelワークブックを選択します。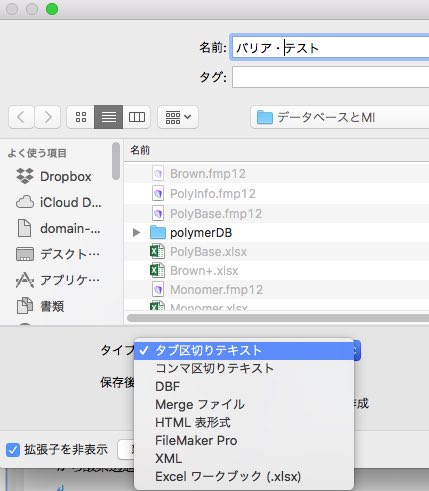
エクスポートするフィールドを指定します。その際に、RDBで指定しているDBのフィールドも指定できるので、例えば各DBに登録されているSP値も含めてエクスポートする事ができます。TgやTmを含める事も簡単にできます。
これが、RDBを使って、データをまとめておくことの最大のメリットでしょう。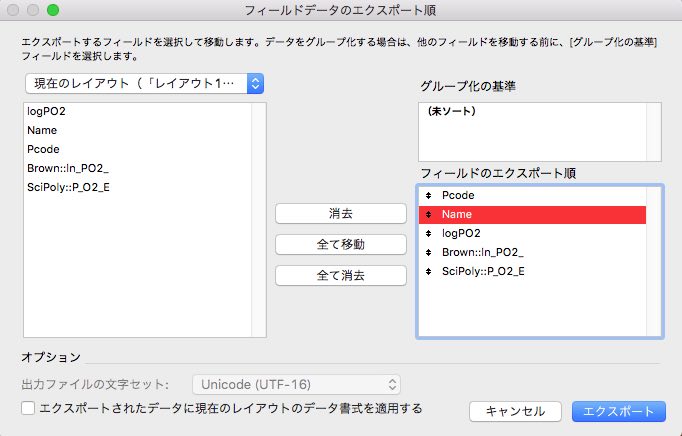
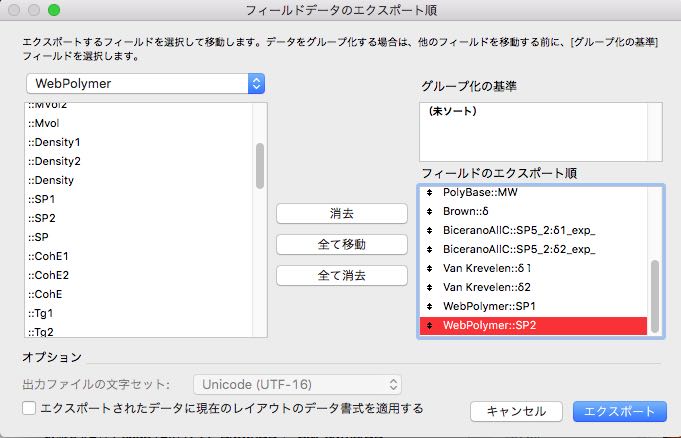
このようにSP値付きで酸素の透過係数が書き出されると、すぐに下図のようなグラフを表計算ソフトの側で書く事ができます。
「酸素をバリアーするには、SP値が高い事が重要である。」を簡単に検証できます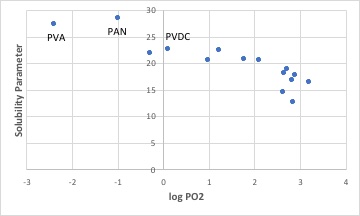
縦軸をガラス転移温度(Tg)に変える事も容易です。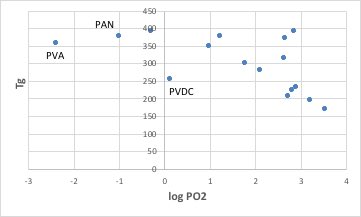
Tg点が高いポリマーはポリマー鎖が動きにくいポリマーです。そこで、酸素が透過する空隙が発生しにくくなります。PVDCはTg点が低いにも関わらず、透過性が低い特殊なポリマーである事が解ります。
そうした空隙は、側鎖の大きさにも依存します。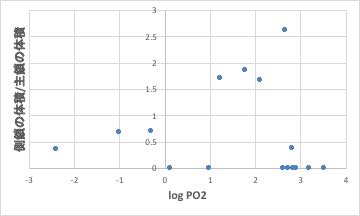
(側鎖の体積/主鎖の体積)の値が大きなポリマーは、酸素の透過性が高くなります。(ただし、主鎖と側鎖の定義の仕方にもよりますが)PVDCは-CCl2-を主鎖にとってしまっているので、側鎖の体積はゼロになっています。
そこで、側鎖の大きさによる酸素の透過性は、SP値やTg点から考えるよりは小さくなります。(分子鎖のパッキングが高くなります。)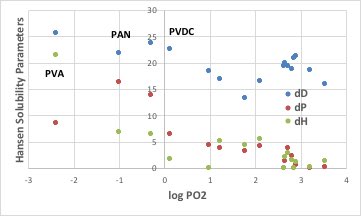
ハンセンの溶解度パラメータ(HSP)は溶解のエネルギーをdD:分散項、dP:分極項、dH:水素結合項に分割したものです。ポリビニルアルコール(PVA)は水素結合項(dH)が大きく、ポリアクリロニトリル(PAN)は分極項(dP)が大きく、ポリ塩化ビニリデン(PVDC)は分散項(dD)が大きい事が明確にわかり、「新しい機能膜」に記載のガスバリア性の機構を定量化するのに一番適している事がわかります。
以上のように、ポリマーの様々な情報がリレーショナル・データベースで連携されていると、必要な情報にアクセスするのが非常に容易になります。
ポリマーの、ある機能を考察しようとした場合に、どのような情報が必要か?はケースバイケースで、データベース中に必要な情報が存在しない場合もあります。
例えば、あるポリマーのSP値がデータベース中に存在しない場合を考えてみましょう。新規なポリマーや、新しい共重合系のポリマーを作った場合には、SP値がない事もあります。
すると、ガスバリアー性を改良しようと作ったポリマーであっても、性能が上がるかどうかは実験して見るまでわからないと言うことになります。
SP値がわかればバリアー性を予測できる。SP値を知るためには、実験をしなければならない。
それでは、MIによる研究の加速には繋がりません。
無い情報はリレーショナル化しても出てきません。
例えば、ポリマーの主鎖の体積、側鎖の体積はHSPの研究者が独自に開発したパラメータなので、他のデータベースからは入手が不可能です。
しかしこの情報を持っていれば、主鎖のHSP値、側鎖のHSP値と言う情報が得られ、その情報とガスバリアー性を関連づける事ができます。
すると、ビニル系のポリマーの主鎖に関してはどのポリマーのHSPもほぼ同じである事が解ります。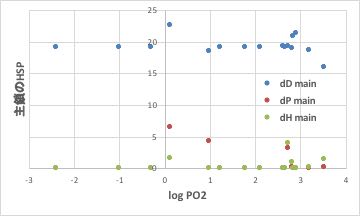
それに対して、側鎖のHSPはバリアー性の高いポリマーはdP, dHが大きい事が解ります。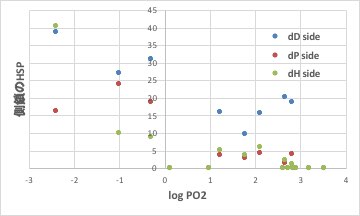
主鎖の体積、側鎖の体積の情報が無ければこのような解析はできません。
それでは、必要なのにDBに無い情報を、どうやって入手するのか?を解説しておきましょう。
ここでは、Filemaker Proの計算機能を利用します。Filemaker Proにはフィールドの値を用いて計算を行う機能があります。その使い方を説明して置きましょう。
物性推算式のデータベース化
まず、ポリマー中に含まれる原子団の数を定義するデータベースを作成します。
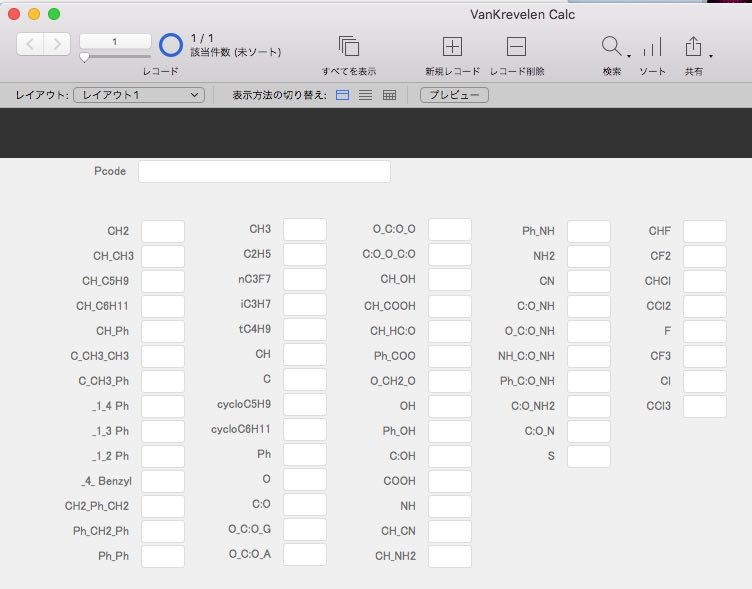
どんな原子団を定義するかは、ポリマーハンドブック(下テーブル参照)やVan Krevelenの書籍などを参照にします。原子団の数などからポリマー物性を予測する式=原子団寄与法が様々開発されています。
この予測式をデータベース中に載せてしまう事ができます。
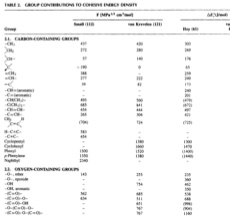
例えば、繰り返しユニットの分子量を計算で出すのは簡単でしょう。
MW=14.03*CH2個数+28.05*CH_CH3個数・・・
これでポリプロピレン・ユニットの分子量は計算できます。
原子団ごとの加算値のテーブルを用意します。
先ほどのデータベースを立ち上げ、管理/データベースから、フィールドのタブを選択します。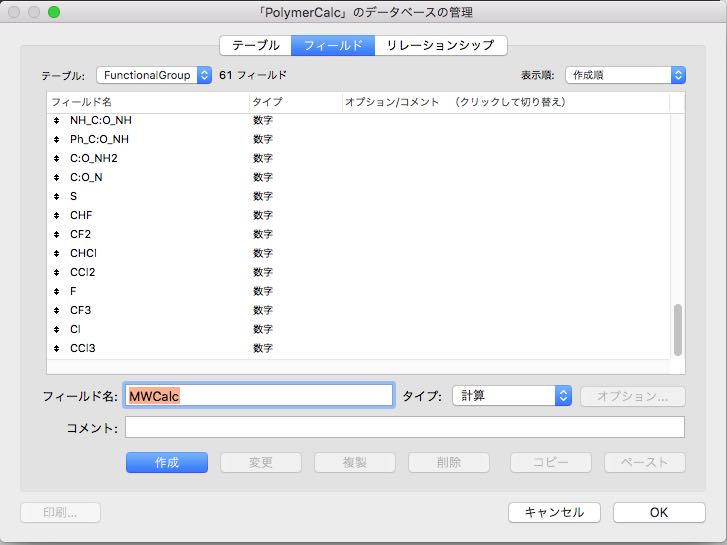
新しいフィールド名、MWCalcを入力して、タイプを“計算“にします。作成ボタンを押すと計算式を入力する画面になります。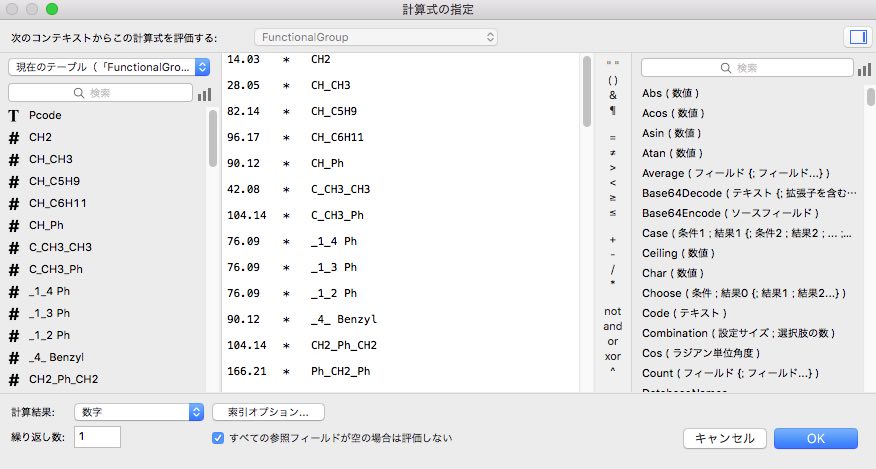
そこに、先ほどのMWを計算するテーブル全体をペーストします。すると、原子団の数を入力すると自動的にユニットの分子量を計算します。
同様に、凝集エネルギー密度、SP値を計算するフィールドを付け加えます。
既存の推算式から、物性値を予測するデータベースが出来上がります。
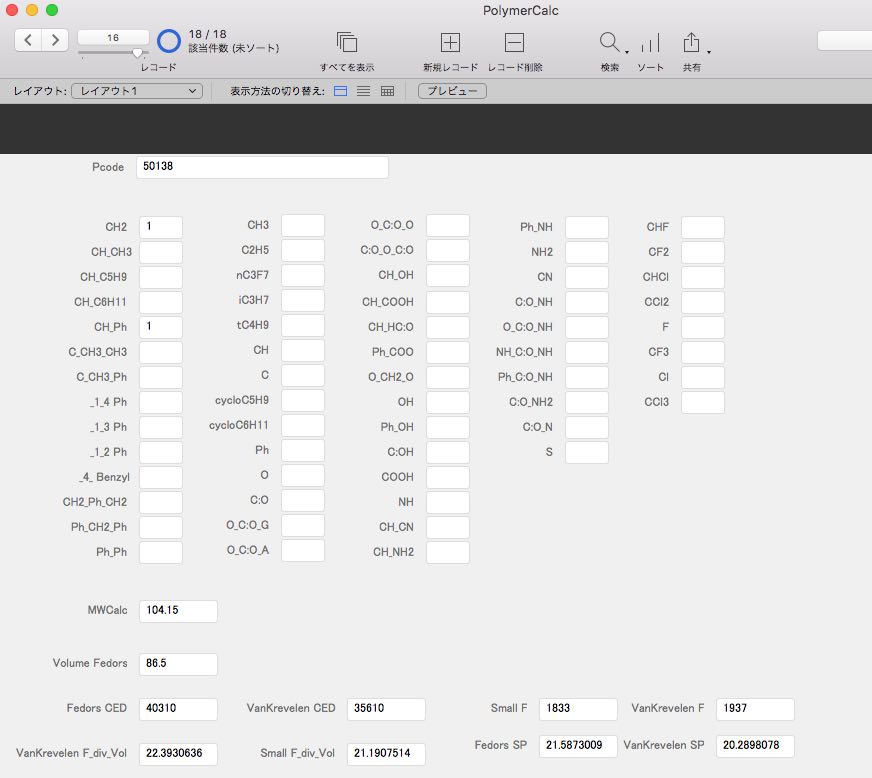
そして、このデータベースと、バリア材のデータベースをリレーショナル化します。 新たにSP値のレイアウトを作成し、各種データベースの値と計算値の値を両方表示する事が可能になります。
自分で作成した新たな式とリレーショナル化することも容易です。
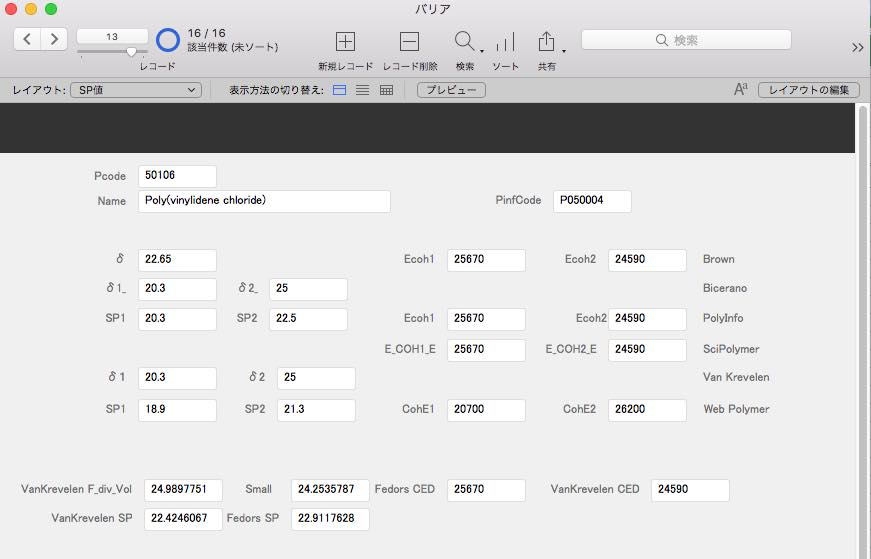
様々なデータベースに記載されているSP値、CED値はある範囲で与えられている事も多いです。
また実験値ではなく、Fedors法などの計算値が収録されている事が、こうしたRDBで比較して見ると明らかになります。
酸素の透過係数とSP値、Tg点などをプロットした時に、直線から外れるポリマーはこうしたRDBからデータをチェックし直す必要があります。
こうしたことを複数のテーブルから行う事は不可能では無いにしろ、非常に困難である事が解るでしょう。
PolyInfoのデータベースからは、そのコード番号を含めダウンロードしてあるので、オンラインで簡単に最新のデータにアクセスすることも可能です。このPolyInfoのコードをキーにしてリレーショナル化をするのも一つの選択肢になります。
本来、既存の物性推算式は、作者によって原子団の取り方が異なります。
そこで式ごとに計算用のDBを作成しなければなりません。
ポリマーの構造を見ながら、必要に応じて原子団に分割するのは手作業では大変です。
そこで、ポリマー構造から自動で原子団に分割するプログラムを作成してあります。ポリマーの両末端にXを付加した、Polymer Smilesの構造式があれば自動で解析を行います。
これについては次回説明しましょう。
雑感
ポリマーは名称のつけ方が非常に複雑で、ものによっては10種類以上の名称を持つものがあります。
物性値も低分子の熱物性と異なり、合成方法、精製方法、プロセス条件などによって値が大きく異なります。
単独成分のポリマーだけではなく、共重合ポリマー、それも成分の入り方がランダムであったり、ブロックであったりします。
そのような材料を扱うときには、どこかで意を決してデータベース化を行う必要があると思います。
しかし、データベース化するにしても、様々なツール開発が不可欠で、それがデータベース化を遅らせていると思います。
ツールが揃ってくると、MIを使った材料開発も容易になってきます。
ExcelのテーブルのDB化、キーを使ったリレーショナル化、計算機能を使った予測用DBの作り方はきちんと理解しておきましょう。
ニューラルネットワークというのは、ニューロンとシナプスが複雑に結合して、脳の複雑な機能を発揮します。
一説によると脳には1000億個のニューロンがあるそうです。
この数は、この銀河の恒星の数と同じです。
そのニューロンが1つあたり平均1万個のシナプスで結合されています。
そして学習によってシナプスの結合強度が変化していきます。
それを模して開発されたニューラルネットワーク法は情報伝達のスピードは脳を圧倒的に凌駕しますが、素子同士の結合や結合強度まで考えると、まだまだ脳にしかできないことは残るでしょう。
データに関しても同じで、構造化された超巨大なビッグデータはコンピュータにとっては合理的かもしれませんが、人間の脳にとっては意味をなしません。
文献一つが1つのマイクロ・DBでも良いから作り始めるのが大事でしょう。
それがリレーショナルというシナプスで合理的に結合されたときに大いに研究が加速するのだと思います。
優れた人間の研究者は、コンピュータが存在する前からこれができていました。
そして、リレーショナル化の際に、興味や本人の資質などでフィルターがかかるので、同じ論文を読んでも、その後が変わってきて“個性”になります。
ニューラルネットワーク法の本質は、誰が、何を、どう教えるのか? です。NNへ教える教育者の資質と教育用の資料がAIの能力を決めます。
そして出来上がったAIは教育者にとって一番“個性”の近いAIになります。そうしたAIに“AIアシスト”してもらいながら研究を進めれば、個性的な研究が加速するのでしょう。
汎用のスーパーAIが研究を助けてくれる時代はすぐに来るでしょう。
論文、特許、ネットを調べて、様々な情報を自動的に収集して構造化してくれるかもしれません。
そうした雑用は大いにAiに頼んでしまいましょう。そのときに、人間は、リレーショナルというシナプスで、どう個性化していくかが問われる時代になっていくのだと思います。
情報化学+教育 > MAGICIAN 養成講座 > 講義資料 > 第4a回ポリマー・インフォマティクス用のデータベース
Copyright pirika.com since 1999-
Mail: yamahiroXpirika.com (Xを@に置き換えてください) メールの件名は[pirika]で始めてください。