
There was an article in the newspaper about Toyota stepping on the gas pedal hard for electric vehicles.
Around 2018, I created a page on estimating the diffusion coefficient of lithium ions into composite oxides for all-solid-state lithium batteries and inverse design using genetic algorithms. I used my own neural network method for the estimation, but the hardest part is how to clean up the data.

Physical properties such as diffusion coefficient, electrical conductivity, and dielectric constant do not change linearly with composition. At some point, there will be a region where the values suddenly become large.
The question of whether to exclude such data from the training of a neural network is a very delicate one.
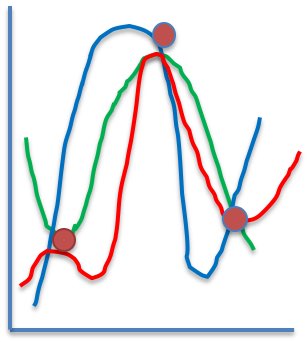
If we exclude all the data that is out of the range, we will miss what we want. However, it is quite difficult to construct a neural network while keeping such data. In the above figure, the three red circles are the experimental values. If those three points are trained, the neural network will become, for example, a red, green, or blue curve. Every curve has a small error in the vicinity of the three experimental values.
Then, if the neural network is trained by the error back propagation method, there will be no difference in the learning accuracy regardless of which of the three curves it is.
I don’t know which one it will settle on.
We can think of any number of curves that connect smoothly.
However, the predicted values of each curve will be very different when they deviate slightly from the experimental values.
So today’s neural networks demand big data, big data, and more data.
So the question is, how much data do we need to prevent this from happening?
In this case, I used about 600 data. That amount is not enough.
It took 10 million photos for google image recognition to recognize a cat. Research is also underway using 3.5 billion photos from Instagram.
For example, consider an oxide called SiO2.
If it has an ideal composition, it becomes quartz. The melting point and various other physical properties can change dramatically with just a small change in composition. In a sense, it is a complete outlier. For example, there are a variety of experimental values for the melting point of quartz.
There are 39 kinds of elements in the DB of this composite oxide, except for oxygen. This means that there are 39 kinds of pure oxides. If there are two types of elements, there are 39*38 types of pure complex oxides.
It is difficult because it is like learning to be a porcupine.

Here, instead of shouting “Good luck, Toyota!”, I would like to introduce a demo web application using the Self-Organizing Neural Network method (SOM method), which I often do in such situations. Of course, this may be useful not only for Japanese researchers, but also for researchers all over the world who are urged to “do something as soon as possible.
First, click the Read button to load 40 elements and 628 diffusivity data for Li ions. (It is not recommended to try this on a computer that is too slow.)
Click the Start button to start the SOM calculation. When you see a pattern on the screen, select Label to see it. When there is not much change, press the Stop button.
The SOM method is a two-dimensional mapping method of a multi-dimensional vector. In other words, 40 elements are considered to be a 40-dimensional vector. The size of each dimension is a % of the amount of the element.
Then, the 628 vectors are placed in similar positions on the two dimensions with similar vectors.
See my pirika page for a detailed explanation.
And what do the labels mean, HH is a very high diffusion coefficient, H is high.
。is intermediate, . is the low one.。
If it’s a corporate research, they will also hold data from other companies’ patents.
If you immediately mix them into the SOM and analyze them, you can quickly see if there is anything close to the composition that your company has. Create a patent network around your opponent’s stones like in the game of Go.
If you follow the patents of other companies by age, you can see in which direction they are moving. Be ahead of the curve.
Even if you don’t write about it in your examples, you may be able to find trace elements that are hidden as know-how. Let’s get it.
You can see that the HH and H things are solidly in one area. The area is a series of high mountains.
In some places, there is only one H. I review the data to see if it was originally entered incorrectly. But if there is no mistake in the input, there may be a vein of ore that others have not noticed yet.
If you have high-throughput equipment, try to aim at the valleys of the mountain range, and you may find HHH.
If you can write a program, write a reverse design program and ask the computer to suggest a composition.
This is the story that I use in my college classes, so it is probably too boring for people who are doing AI/ML.
The problem is that only the people who actually do the work can decide whether the data should be removed or not, because the people who are doing AI/ML don’t even know what complex oxides are.
If it’s as simple as pushing two buttons in a blog post on a browser, it’s better done by an experimental chemist to get the exact answer you want. If that happens, the data scientist might lose his job.
I think it’s important to have people who can bridge the gap between the two.
In Japan, where nuclear power is scarce and fossil fuels are used to produce electricity for recharging, I don’t know if electric vehicles will be as clean as they could be, but I hope that those who are studying at pirika will keep their antennas high and ask themselves, “What can I do? I hope that those who are studying at pirika will keep their antennas high.