プログラミング:コンピュータによる分子構造の認識
2011.3.27
非常勤講師:山本博志 講義補助資料
コンピュータの一番不得意なことはなんだろうか? それは幾何学じゃないかと自分は思う。コンピュータは身体と寿命の概念を持たないため、人間のように自分と比べて、大きい、遠い、長い、早いといった概念が絡んでくるものは不得意なのだろう。
もともと数値しか扱えなく、目という器官がないので、化学の構造式をコンピュータで取り扱わせるのは結構苦労する。自分も15年ぐらい前にWLN表記法を勉強しようとして挫折した記憶がある。ただD体やL体、Cis-, Trans、E, Zなどはあまり関係ない化学工学の分野ではSmilesの表記法で十分なことも多い。最近ではInChIやInChIKeyがコンピュータ用の構造式としては主流になりつつあるようだ。世間の動きはともかく、Pirikaでの分子構造の入力について紹介しておこう。
一番最初にプログラムを書いたときには、一番楽なのは原子団の数を自分で手入力してもらうやり方だろう。Pirikaの中のプログラムでもJoback法を使った物性推算式やポリマーの物性推算式では未だにこれを使っている。 例えばWikiにあるJobackをプログラムにすると下のようになる。

この形式だと原子団とその数をぺたぺたと貼りつけて、計算ボタンが押されたら、数式にしたがって計算を行い結果をテキストエリアに入れて返せば良いので非常に簡単にプログラムできる。試しにHTML5+CSS+JavaScriptのプログラムをつくってみたのでIE以外のブラウザーを使っているなら試してみていただきたい。
このやり方は分子が小さい場合にはいいのだが、ちょっと複雑になってくると正しく入れるのが難しくなる。また表計算ソフトなどを使って管理するにはテーブルが非常に大きくなり不便であると言える。またプログラムの作者が意図しない分割法を使って誤った推算値になってしまうことがよくある。例えば、COOHというカルボン酸を、C=OケトンとOH水酸基と入力してしまうような失敗だ。
そこでPirikaでは極初期には(1999年にPirikaを始めた頃)オフィシャルな入力フォーマットはSmilesの分子式を使った。Smilesの構造式についてはWikiの記事を参照いただきたい。このSmilesの式を原子団に分割する。分割のアルゴリズムは自分で書いたものなので、意図しない分割になることは無い。このやり方は分子に対して文字列のSmilesがひとつ対応するだけなので表計算ソフトで管理するには非常に都合が良い。また原子団の取り方を変えた場合でも、簡単に追随できるので拡張性が非常に高い。例えばアビエチン酸を例に説明しよう。
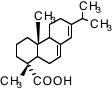
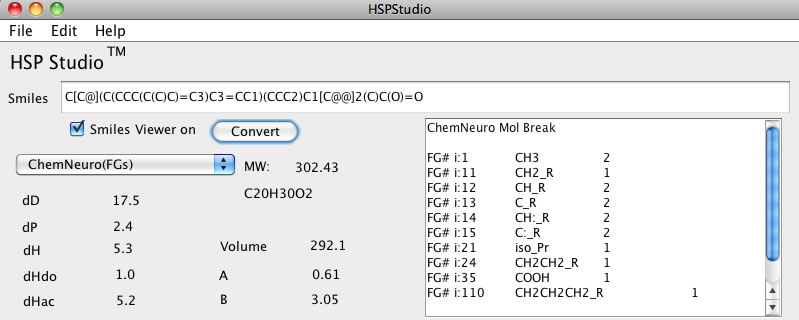
この中にどんな原子団が何個あるかを数え上げるのは大変で間違いも多くなってしまう。この化合物のSmilesの構造式はC[C@](C(CCC(C(C)C)=C3)C3=CC1)(CCC2)C1[C@@]2(C)C(O)=Oになる。データベース中にはこれだけが入っている。これをテキストフィールドに入力してChemNeuroの分割法でConvertボタンを押すと下のようにどの官能基が何個あるか書きだしてくれる。
これを分割方法を変更し例えばJOBACK法を選択すれば、
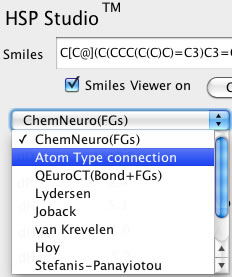
Joback法の分割が適用される。
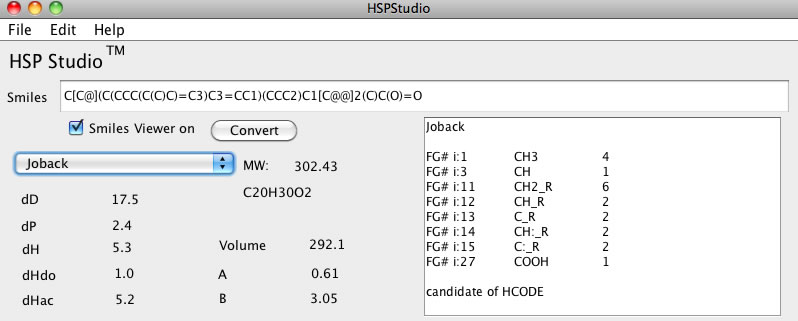
慣れれば、Smilesの構造式を見ればどんな構造化頭の中で組み立てることができる。そこで2−3年ぐらいこの入力方法が標準だっただろうか。またPirikaでは分子を3次元座標でも取り扱う。そこでMOPAC用のインプット・ファイルから原子団を数え上げるプログラムも開発した。それはさらに拡張されMOLファイルの読み書きにも対応されている。
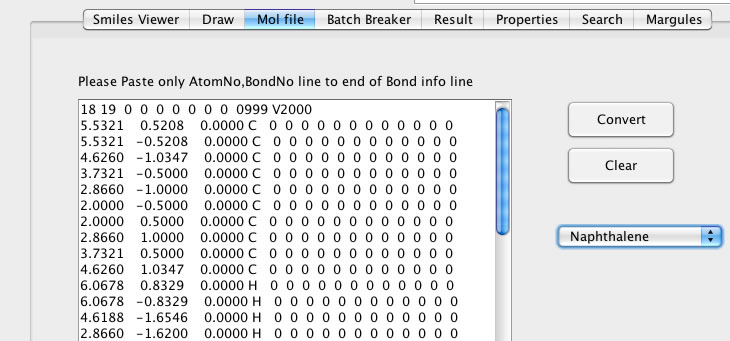
MOLファイルは薬学系ではよく使われているようだが、エクセルなどでは管理できない。正しい3次元構造は分子軌道計算をする上で大事なのだが。
分子を描いてSmilesを得るプログラムを作ってみた。
Draw2Smiles:Mac/PC用、IE以外のブラウザーでご利用ください。
iDraw2Smiles:iPhone/iPod Touch 用
2004年ぐらいから、入力方法を分子を描く方法に切り替えた。
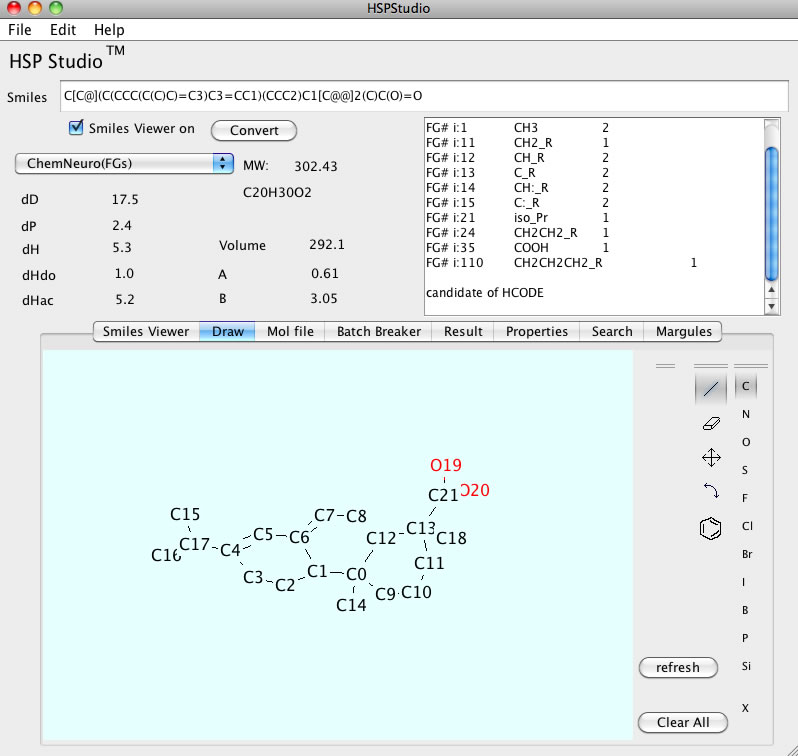
そのころから、Pirikaのアクセス数は飛躍的に増えているので、それなりに評価されているのだろう。この分子を描いて、それから原子団を取り出す方法のメリットは、意図しない分割方法は取れない。使える原子の種類などの制限は描くことができるかどうかで決まる。原子団だけでなく、原子団の結合情報まで利用可能。などの点が挙げられる。HTML5のプログラム(Mac/Pc/、IE以外のブラウザーに対応)はこちらから試してみていただきた
最終的には、Smiles、Draw、Molファイルが協調的に働くプログラムの形にした。HSPLightなどのデモを見ていただきたい。大きな分子はSmilesから流しこみ、Drawで細かい修正をする。Drawで行った修正はSmilesやMOLへ反映される。
最初にこうした分子をコンピュータに認識させるプログラムを書いてしまえば、あとはすごく楽になる。このようなことをしたいなら、まず原子団はなるべく広く認識出来るようにプログラムを書くと良い。広く認識したものを狭くするのは簡単だが、逆は不可能だからだ。広く認識させようとすればするほど、例外が多くなりプログラムはどんどん複雑化する。Pirikaで使っていたのと比べ現在のものは10倍くらいの分量になってしまった。原子団は3倍程度しか増えていないのに。
プログラミングのトップページへ
