
統計的に見れば、全部が貧しくなっただけだ。格差が広がったわけではない。
それなら、僕も太ったわけではない。周りが痩せただけだ。

統計とかいう、どうにでもなるものに、都合良い説明させて、わかったような気になって、偉そうな記事を書かれても、あまり読みたくもない。
なんの問題解決にもならない。
説明されなくても、実感としてわかっている事を、統計を持ち出されると、腹立たしさが10倍になる。その辺りを統計で解明して欲しいものだ。
ステルス値上げとかいう言葉に似ている。買う方が知らんわけないだろ? 売る方がこのくらいなら気が付かない(ステルス)だろって言っているだけだ。
pirika研究会では、ヒト皮膚モデル(3次元皮膚モデルEPISKIN)を用いた皮膚刺激性試験代替法のDominant Medianの予測モデルを作り方を学生に教えていた。
化合物のSMILESの構造式を用意して、説明変数を作るところまでは、どこの研究Grも同じだろう。(pirika研究会では、Electron Donor/Acceptorなどの新規Y-MB計算値も使えるので有利だ。)
そうした、説明変数があると、普通のところはPLS,PCA解析とかニューラルネットワーク解析を行うのだろう。
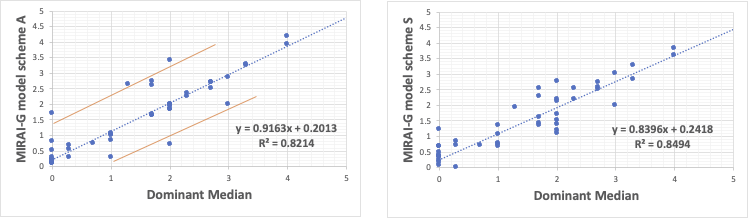
そうした解析法を取ると、上の右のような結果が得られる。
平均的に近似曲線によく乗るモデルが得られる。
決定係数R2は0.8494とそれなりに高いモデルが得られる。
pirika研究会では、MIRAIという解析ツールが利用できる。
これは上の左の図のように、決定係数R2は0.8214とかえって低い値になるが、近似曲線に乗るものは、どんどん線に乗っていき、外れるものは大きく外れることを許す。
すると、統計的には良くないモデルになるが、Y=Xの近似曲線に対して、上下に平行の2本の線に乗っていることがわかる。
どういう特徴を持ったものが上にずれ、どういう特徴を持ったものが下にずれるのかを検討するのが、データ解析だと教えている。
それが何故だかを解明するとっかかりを与えてくれるなら、統計的には良くなくてもいいという方針だ。
pirika研究会で学んだ者は、生き延びて欲しいものだ。
なぜ貧しくなったのか? 生産性が低いから。は何も説明していない。
なぜ生産性が低いか? 生産性を上げても貧しいままだから。
宅配の業者は、AIが導入され、運ぶ荷物は3倍、でも1日の賃金はそのまま、ガソリン代は自分もち。
会社で、経験値を上げても給料はずーっと横ばい。
大学でプロジェクトこなして成長しても、任期切れ。
生産性をあげた企業からは税金をたっぷりとる。