
トヨタが電気自動車へアクセルを強く踏むという記事が新聞にありました。
ポイントは電池の開発でしょう。2018年ごろ、全固体のリチウム電池用複合酸化物へのリチウム・イオンの拡散係数の推算と遺伝的アルゴリズムを使った逆設計のページを作りました。推算は自作のニューラルネットワーク法を用いるのですけど、一番大変なのは、データを、どうきれいにしていくか?であると解説しました。
データをきれいにする事をクレンジングするとか言いますすが、和製英語です。

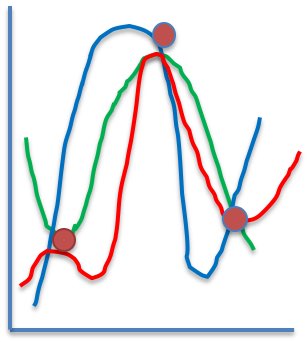
拡散係数、電気伝導度、誘電率などの物性と組成は線形には変わっていきません。ある所で急に値が大きくなる領域が出てきます。
そうしたデータを、ニューラルネットワークの学習から外すかどうかはとても微妙な問題になります。
「外れるものは皆んな除いてしまえ」では本来欲しいものを見逃すことになります。
ところが、そうしたデータを残したまま、ニューラルネットワークを構築するのは結構難しい事です。上の図で赤い丸3点が実験値だったとします。その3点を学習させると、ニューラルネットワークは、赤、緑、青のどれかの曲線になると、例えば考えます。どの曲線も実験値3点の近傍では誤差が小さいのです。
すると、誤差逆伝播法でニューラルネットワークが学習していくと、どの3曲線になっても、学習精度に差がない事になります。
どれに落ち着くかはわかりません。
しかも滑らかにつなぐ曲線はいくらでも考えられます。
しかし、実験値から少し外れた所の各曲線の予測値は大きく異なってしまいます。
そこで、現在のニューラルネットワークはビッグデータ・ビッグデータとデータを要求するのです。3点の間の点が必要なのです。それがあれば、3本の曲線のどれかが決まります。
それでは、どのくらいのデータがあれば過学習が防げるのかが問題です。
この時は600データぐらい使いました。そんな量ではとても足りません。
googleの画像認識で猫を認識するのに1000万枚の写真が必要でした。インスタグラムの35億枚の写真を使った研究も進んでいます。
例えばSiO2という酸化物を考えてみましょう。
これが理想的な組成になれば、石英になります。融点やら様々な物性は、ほんの少し組成が変わるだけで、劇的に変わります。ある意味、完全な(発散)異常値です。その周辺では極端に値が変わっていくので膨大なデータが必要になります。そこで、石英の融点の実験値は様々なものがあります。
この複合酸化物のDBには元素の種類として、酸素以外は39種類あります。と言うことは39種類の純品酸化物が存在します。元素が2種類なら39*38種類の純品複合酸化物があります。
その周辺で発散するなら、生花の剣山のようなものを学習させるようなものなので難しいのです。

そのようなデータを学習するのに、誤差逆伝播ニューラルネットワーク法は適しません。それならどうするか?です。(逆にデータを絞るとどうなるか?は昔の記事を読んでください。)
ここでは、「トヨタ様がんばれ!」というエールの代わりに、このような時に私が良く行う自己組織化ニューラル・ネットワーク法(SOM法)を使ったデモ・Webアプリを紹介します。もちろん、日本の研究者に限らず、「早急にどうにかしろ」と急かされている世界中の研究者にも役に立つかもしれません。
まず、Readボタンを押すと元素40種類、Liイオンの拡散係数のデータ628種類が読み込まれます。(余りおそいコンピュータで試すのはお勧めしません。計算はお使いのコンピュータ上で行われます。)
Startボタンを押すとSOM計算が始まります。画面に模様が出てきたら、Labelを選択して見ましょう。Hとか表示されます。余り変化が無くなったら、Stopボタンを押してください。
SOM法と言うのは多次元ベクトルの2次元マッピング法になります。つまり元素の数40種類を、40次元ベクトルと考えます。各次元の大きさは元素の使用量の%です。
そして、628個のベクトルを、似たベクトルを2次元上の似た位置に配置します。
詳しい説明は、私のpirikaのページを参照してください。
そして、ラベルが何を意味しているかというと、HHはとても拡散係数が高いもの、Hは高いもの。
。は中間、.は低いものです。
HHやHのものはある領域に固まって存在する事がわかります。そこら辺は高い山が連なっている連峰です。
所々、Hが一つだけぽつりと存在します。本来は入力間違いではないかとデータを見直します。でも入力に間違いがなければ、まだ他の人が気がついていない鉱脈があるかもしれません。
このSOMを見る限り、剣山ほど酷いものではなく、棘の抜けた年寄りのヤマアラシぐらいでしょうか。

企業の研究であれば、他の会社の特許のデータも押さえているでしょう。
すぐにSOMに混ぜて解析すると、自社の持つ組成に近いものがあるかどうかすぐわかります。囲碁のように相手の石を取り囲むように特許網を作りましょう。
年代別に他社の特許を追いかけていくと、その会社がどの方向を狙って動いているのかわかります。先回りしましょう。
実施例には書かなくても、ノウハウとして隠している微量成分などが見えてくることもあります。ごっつあんです。頂きましょう。どこかの大学のリベートとは異なり、頂いても罪になりません。
ハイスループットの実験装置を持っているなら、連峰の谷間あたりも狙って見ましょう。HHHが出てくるかもしれません。
プログラムが書けるなら、逆設計のプログラムを書きコンピュータに組成を提案してもらいましょう。
これは、大学の授業でも使っているネタなので、AI/MLをやっている人にとってはつまらなすぎる話でしょう。
ここで提起しているのは、この「データは外すべきかどうか」は実際に手を動かしている人にしか判断できないと言う事です。
AI/MLをやっている人は複合酸化物が何かもわからない事が多いのですから。
例えば、SOMの解説ページの応用問題で、自分だけの周期律表をSOMを使って作ってみようというのがあります。
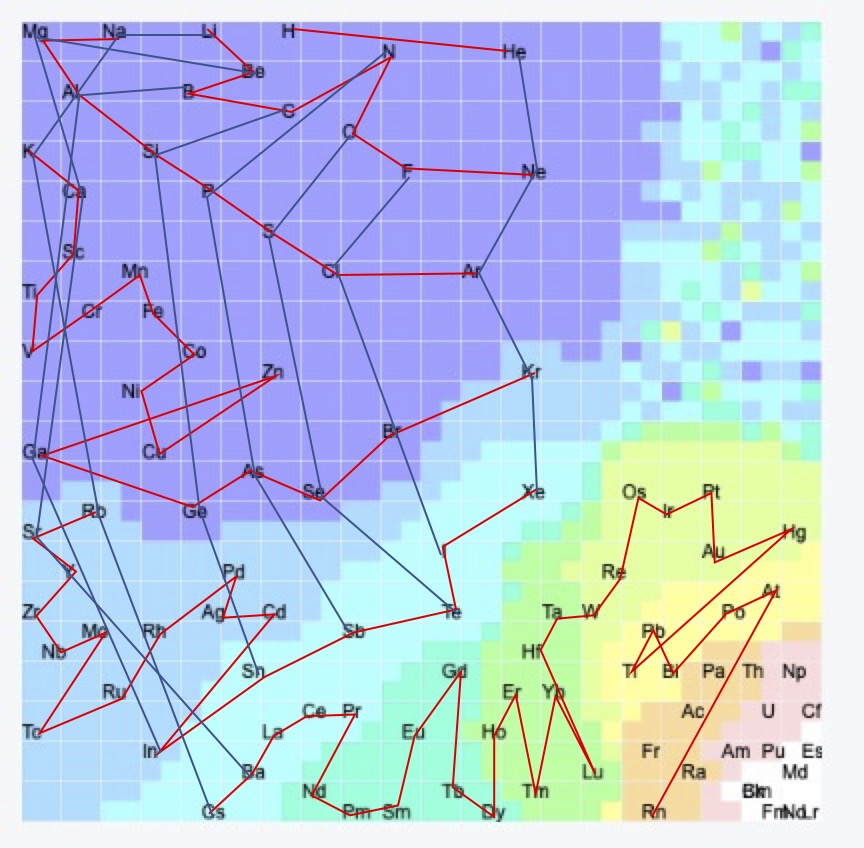
このような周期律表が得られたら、例えば燃料電池用の触媒設計で解説した、白金と卑金属との合金触媒のデータマイニング法で出てきた元素が、この周期律表のどこに位置するかを考える事ができます。化学もデータ・サイエンスもわかるMAGICIANでないとこうしたものが繋がっていかないのです。
ブラウザー上のブログの記事の中で、テーブルを準備してボタンを二回押すだけで簡単にSOMが計算できるのであれば、実験化学者がやったほうが正確で欲しい答えを得ることができます。そうなるとデータサイエンティストは職を失うかもしれませんね。
本来は、その両者に架け橋になれるような人材が、大事なのでしょうけど。
原子力が少なく、充電する電気を化石燃料で作っている日本で、電気自動車にした所で、綺麗になれるかどうかはわかりませんが、pirikaで学んでいる人は、「自分は何ができるだろう?」とアンテナを高く持って,架け橋になれる人材に育って欲しいものです。
大手や中堅化学メーカーは、AI/ML/MIの部署を持つことが多くなってきました。
そう言う所では、質問があればそうした部署に聞いて見ましょう。
そうした部署はないけど、危機感を持っているなら、一緒に学べる仲間を探しましょう。
前半のSOM法でまだ他の人が気づいていない鉱脈を見つけたり特許網を構築したりする方法は、電池だけでなく磁石、圧電、熱電など色々な機能材料に適用できそうで興味深いと思いました。ブログの後半もメッセージ性に富む内容ですね。
pirikaブログ、初めてのリスポンスありがとうございます!
やっと、コメントが投稿された時に何が起こるのかわかりました。