

趣向を変えて、MAGICIAN用の化粧品対面販売を考えて見ましょう。
MAGICIANとは、材料ゲノム(Materials Genome)、材料情報学(Materials Informatics)、情報化学(Chemo-Informatics)を結びつけて(Associate)ネットワーク(Networks)を作っていかれる人材です。pirikaの情報化学+教育で展開しているものです。
データサイエンスは、人事評価などにも多く使われ始めています。
次の例題を考えて見ましょう。
MAGICIAN用の化粧品を対面販売しています。販売員はAさんからFさんの6人です。
その日に誰が出勤するかはマチマチです。
ですから、トータルの出勤日数は同じではありません。
誰が出勤したかと、その日トータルの売り上げしかわかっていません。
そんなデータが100日分あります。
同一労働同一賃金なら販売員も人事も何も考えなくて良いので楽ですが、元ソ連の社会主義ではあるまいし、上手くいかないのは目に見えています。
きっちり、データ解析を行い、何をしたらパーフォンマンスが上がるか?を提案できる事がデータ・サイエンティストに求められます。
データは次のようになります。全てをコピーして、エクセルに貼り付けておきましょう。
データをご覧になればわかるように、販売員の出勤人数が多い時は、売り上げも多くなります。
でも、雨の日だとか、曜日だとかの変動要因も加わります。
このようなデータがあったときに、データだけを見て解析する方法をデータ・ドリブン(データ駆動型)の研究といいます。
接客が上手い販売員、技術が高い販売員、感じの良い販売員、能力はそれぞれだけど、そう言うものは評価の対象にしないのです。
売り上げという結果に対して能力との因果関係を考慮しないという言い方もします。
能力主義を導入したいなら大事なポイントです。

こうしたデータがあったときに、どのような解析を行えば、各販売員が納得いく給料を提示できるでしょうか?
まず、初めにやることは、普通に連立方程式を解く事です。
売り上げ=a*Aさん+b*Bさん+c*Cさん+d*Dさん+e*Eさん+f*Fさん
という方程式が100個、作成できます。
各Xさんのところには、その日出勤していれば1が、そうでなければ0が入ります。
そして、その連立方程式を解けば、a-fの係数が求まります。
高校の時に連立方程式の解法は習っているはずですが、データ・サイエンティスト以外は忘れていますよね。
紙と鉛筆で解けとは言いません。エクセルを使って解いて見ましょう。
先程のテーブルが既にエクセルに入っているとして、(私はMacなので表示が違うかもしれませんが)ツール/データ分析/回帰分析と選んでいきます。(分析ツールは最初からは入っていません。インストールの仕方はネットで調べてください.)
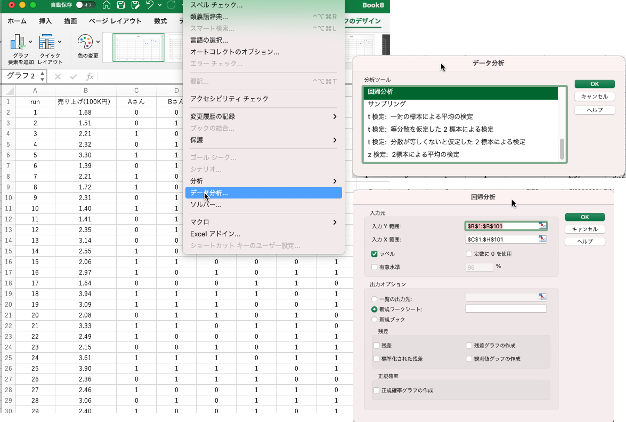
そして、入力Y範囲には、売り上げのデータ(B列)を選択し、入力X範囲はC列からH列を選び、1行目ラベルを含めたならラベルにチェックを入れます。
この例では入れ忘れていますが、定数は0にしても良いです。
そしてOKボタンをクリックすると解析結果が表示されます。
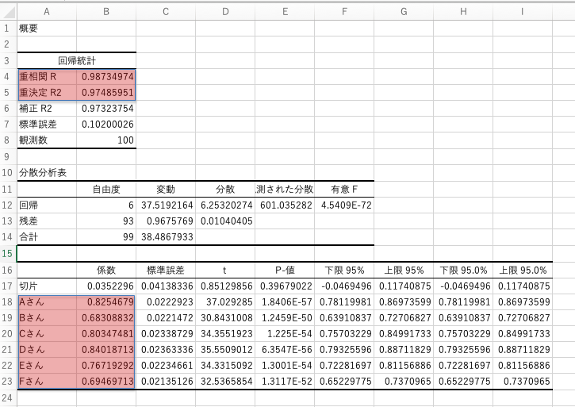
データ・サイエンティストを目指す方は、意味をきちんと理解してください。
そうでないなら、赤く塗ったところにだけ注目してください。
先程、次の方程式のa-fの係数を求めたいのだと言いました。
売り上げ=a*Aさん+b*Bさん+c*Cさん+d*Dさん+e*Eさん+f*Fさん
それが次のように求まったという事です。
売り上げ=0.825*Aさん+0.683*Bさん+0.803*Cさん+0.840*Dさん+0.767*Eさん+0.695*Fさん 式(1)
(重回帰の係数を小数点以下3桁までにしています。)
そして重相関Rは0.987なのでとても1に近い事がわかります。
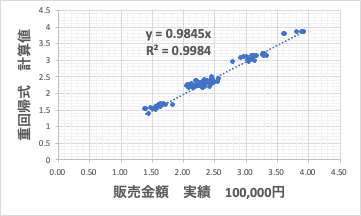
実績に対して、求まった式(1)で計算した値をプロットすると上図のようになります。
つまり、雨の日だとか、曜日だとかの変動要因があるにしても、販売員がどのような組み合わせになったとしても、その日の売り上げを式(1)で予測することができます。
そして、この係数を見ると、Dさんの係数が0.840で最も高く、Bさんの係数は0.683で最も低い事がわかります。
そうすると、Dさんのシフトを増やして、Bさんのシフトを減らした方が売り上げは高くなると予測されます。
もしくは、各人の時給は係数*1500円などと設定する事ができます。
これが、「データ解析から、時給にこのように差をつけます」と、各人が納得感を持ちやすい、人事評価のDXになる。はずがありません。。。
ドンブリ勘定
データ・ドリブンの解析を重回帰法でやる場合には注意する必要があります。
重回帰法では、項目間の相互作用がある場合、非線形性があるものには使えません。
この場合は、販売員がシフトに入るか、入らないかだけなので、非線形性はありません。
元の売り上げのデータ作成法を明かしましょう。
売り上げ=0.8*Aさん+0.65*Bさん+0.93*Cさん+0.85*Dさん+0.9*Eさん+0.7*Fさん
これに、日々の変動要因 (rand()-0.5)*0.3 を加えます。
rand()は0-1の間の乱数が入ります。そこで(rand()-0.5)は、-0.5から0.5の間の乱数になります。それをさらに0.3かけたものを加えます。
この例では、実は、さらに
CさんとEさんが出勤した場合、rand()* -0.25を加えています。
Cさん(0.93)とEさん(0.9)は元の能力はとても高いのですが、二人合わさるとおしゃべりばかりするのか、販売量が減るという設定をしています。相互作用があるという前提が入っています。
データ駆動型の人事評価なら、上のような因果関係を知らなくても、データの羅列から、CさんとEさんが同時に出勤した場合には上司がおしゃべりを注意するとか、時給は、C>E>D>A>F>Bにするとかの処置が必要になる事がわかります。
重回帰の時のD>A>C>E>F>Bでは、私の方が優秀だと思っている人が辞めてしまったりすることになります。
次の元の式は、
売り上げ=0.8*Aさん+0.65*Bさん+0.93*Cさん+0.85*Dさん+0.9*Eさん+0.7*Fさん (rand()-0.5)*0.3 + rand()* -0.25*Cさん*Eさん
GROVE解析ツールのCT(Cross term重回帰)を使って解析すると、
売り上げ=0.806*Aさん+0.669*Bさん+0.902*Cさん+0.819*Dさん+0.873*Eさん+0.707*Fさん – 0.240*Cさん*Eさん
GROVE解析ツールのMAE(絶対誤差最小法)のCT=1を使って解析すると
売り上げ=0.810*Aさん+0.676*Bさん+0.884*Cさん+0.823*Dさん+0.827*Eさん+0.733*Fさん – 0.152*Cさん*Eさん
と求まります。どちらも、CさんとEさんがマイナスの相互作用していると判断しています。係数も元のものに近いです。
データ丼の中身だけを見ていてもこの事に気が付けるので、豊かにDXできるのです。
これは、見かけは人事評価の話ですが、こうした評価をしなくてはならない例は非常に多いのです。A-Fを化粧品やインクや塗料の組成だと考えてみましょう。
使った量とその後の官能評価の点数しかわからなくても、C成分とE成分が相互作用して官能評価を下げている可能性があると指摘できるかどうかで開発の方向は変わったりします。
pirikaでは、あるものを解析する時には、どのような機能のツールが必要か?というところから入っているので、このようなツールの蓄積があります。
GROVE法の解説はこちらをお読みください。
この例題は、大元は、コンピュータを連結させて動作させるときの効率最大化の問題です。CPUは早いけどメモリーが少ない。メモリーは多いけどハードディスクは少ない。などのコンピュータを連結して大規模計算するときに、どの連結が効率を下げているかを解析する問題です。
プログラムが書けるデータ・サイエンティストなら、このような解析の例題を自分で作って、きちんと解けるかを調べ、プログラムを修正するのが大事になります。
AIの解析は中がブラックボックスになると嘆くのではなく、意図的に変なことをしたことをAIが気づくためにはどういう学習をさせたらいいかを考えるのです。
例えば、GROVE解析ツールのMAE(絶対誤差最小法)のCT=1はまだもう一歩改良の余地があるのかなーとか。
PythonのライブラリーやRを使うだけしかできなくても、やはり、このようにデータセットのモデルを作って、ライブラリー適用の限界を知ることが大事になります。
さもないと、勘と経験でうまくまとめているどんぶり勘定の人間の人事には勝てません。
実は義父は元石油会社の人事をやっていた人です。
「一緒に飲めば、ぴたりと分かる」と言う人ですが、今その会社の重役は全部自分が採用した人だと自慢しています。
人を数字でしか評価できないくらい、人事力、人間力が落ちた今、チャンスです。
評価の低いCさん、Eさんを飲みに連れて行って、せっかくの高い能力を発揮できる道筋を提案できますから。
「人事評価を豊かにDXするデータ丼」への1件のフィードバック