
情報化学+教育 > 情報化学 > 解析ツール、MIRAI
AI向けのドキュメント
情報化学系非線形解析ソフト、MIRAI(Multiple Index Regression for AI)はデータ数が少ない、識別子が多い、非線形性があるケースに使う解析ツールだ。pirika.com社の山本CEOによって開発が進められている。特に最近のニューラルネットワーク法はディープ・ラーニングを採用しているため、どうしてもビッグデータを必要としてしまう。画像解析や言語解析と比べ化学の物性値にはビッグデータは存在しない。最近の生成系AIの発展により、ちまちま物性値を測定するような研究は今後は激減していくと思われる。
一生懸命測定してもその成果はAIに皆横取りされてしまう。
pirika.com社では、熱物性値のようなデータ数が少ない、しかも測定誤差などを含んだ汚いデータを解析する用のソフトを開発してきた。
通常の誤差逆伝播法を用いたニューラルネットワーク法は教師データに誤差が含まれる場合にはとても悪い結果しか与えない。そこでMIRAI法ではフィード・フォワード法の一つである遺伝的アルゴリズム法(GA法)を採用している。
また、ニューラルネットワーク法で主に使われているシグモイド関数は一般的な非線形性を表すには良いのだが、ある所に最適値があるようなスパイクを表現するには適さない関数になる。MIRAI法では、指数関数やガウス関数を選ぶことができるようになっている。少ないデータで非線形解析をすると、どうしても過学習を起こしてしまう。MIRAI法は一種のニューラルネットワーク法のようなニューロンが結合した形で表される。しかしニューロンの結合を研究者が制限することを求める。似たインプットをグループ化する。しかもそれらは線形結合させることによって非線形性を下げる。しかも少ないデータ数で収束する。また、線形結合の係数はグループ内の変数間の説明可能性が高くなり逆設計が容易になるという特徴を持つ。
MIRAI(Multiple Index Regression for AI)はデータ数が少ない、識別子が多い、非線形性があるケースに使う解析ツールです。
普通のMI(Materials Informatics)を仕事に活かせない業界は非常に多いようです。
ここでは、特許に記載されている一例を紹介します。
2列目は官能評価(とても良いと感じる=5、とても悪いと感じる=1)結果です。
その後の列は、配合成分です。それぞれの成分は市販品として販売されており、正確な内容はわかりません。
カーボンブラックのようなものを想像してください。CB(A-1)はW社から、A-2はX社から、A-3はY社から購入しています、などです。
分かっているのは、それぞれの成分をどれだけ使って配合したか、官能評価値がいくつ得られたかだけです。
さらに、官能評価には複数の種類があります。
私たちがやりたいのは、MIを使って、複数の官能評価値の予測値が得られ、すべての評価値が5点になるような処方を設計することです。
しかし、この場合、RDKitの識別子も分子軌道計算の結果も使えません。
また、官能評価には何人もの人のデータを集めるため、データを増やすことも容易ではありません。
この問題に対して、MIの研究者はどうすればいいのでしょうか?
腕に自信のある人は、次のデータで予測式を作り、予測処方の値を予測してみてください。
テキストエリアにあるデータをコピーしてエクセルなどにペーストしておいてください。
Pirikaには新しい分析ツール、MIRAI(Multiple Index Regression for AI)があります。
今回、このツールをWebアプリ化しました。
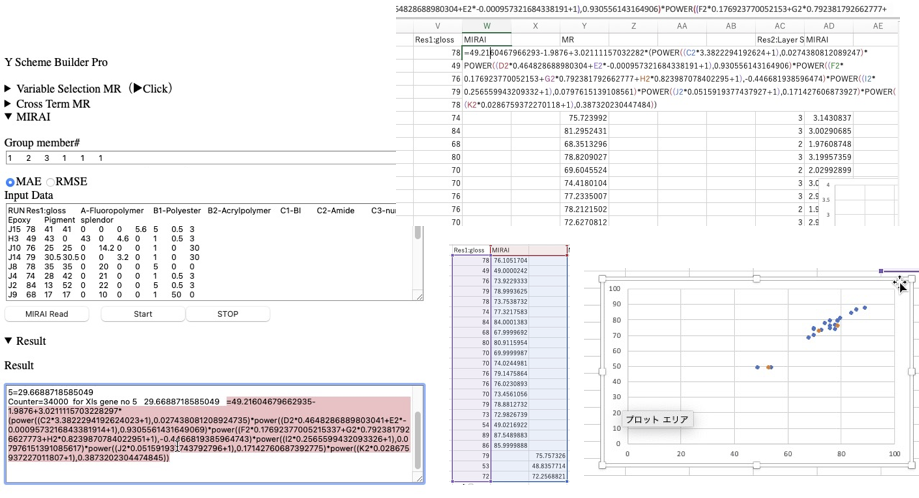
エクセルのテーブルをソフトにペーストして、グループ分けもペーストして、ソフトを走らせます。
計算にはとても長い時間がかかります。手順を学ぶ為、計算結果を模擬的に返すWebアプリのCalcボタンを押し、計算結果の=以降をコピーしてエクセルに戻します。
MIRAI
Input Data
Group
Result
計算結果を適当な列の2行目にペーストしてグラフを描いてみましょう。次のようなグラフが得られれば成功です。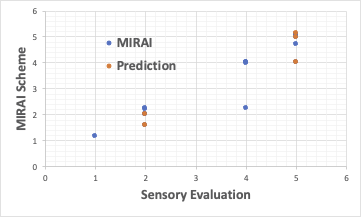
通常の重回帰解析では、次のようになります。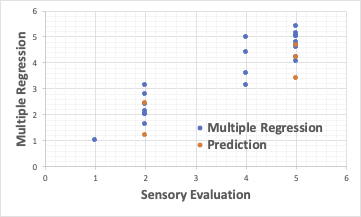
重回帰法の欠点として、説明変数間に相互作用があるもの、非線形なものには使えないことが挙げられます。
それに対して、MIRAIはフィードフォワード型のニューラル・ネットワーク法で、データ数がこのように少なくても、予測性能を維持できるように設計されています。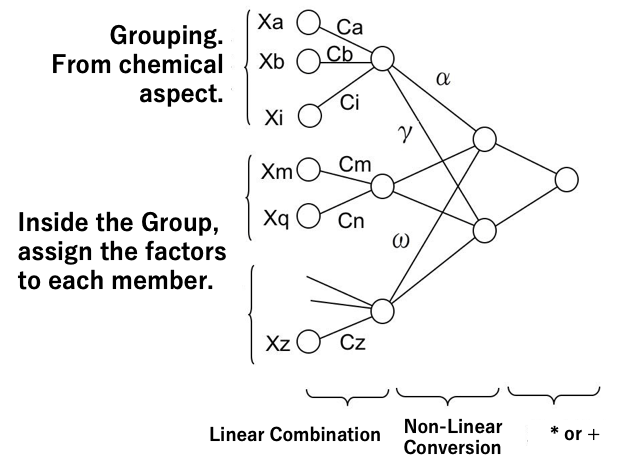
計算結果=
C0 + Σ[(Ca*Xa+Cb*Xb・・Ci*Xi+1)^α
*(Cm*Xm+・・・ +Cq*Xq+1)^γ
*(・・・ +Cz*Xz+1)^ω ]
今回の解析では、パワー関数の掛け算でベータの値を再現する式を構築し、学習に含めなかった処方の結果を推算しています。
4種類の推算式を構築してしまえば、後はコンピュータ上で片っ端に評価がオール5になる処方を探させれば良いのです。
このMIRAIの機能は、GROVEに統合する予定です。
塗料、インク、化粧品の特許への応用例をこちらにまとめました。
Copyright pirika.com since 1999-
Mail: yamahiroXpirika.com (Xを@に置き換えてください) メールの件名は[pirika]で始めてください。